Texto universitario

_____________________________
Módulo 2: Conceptos vectores y matrices
2.1 Vetores y matrices
Los vectores y las matrices son útiles para representar datos numéricos multivariados, y ocurren naturalmente al trabajar con ecuaciones lineales o al expresar relaciones lineales entre objetos. Los algoritmos numéricos para una variedad de tareas involucran aritmética de matrices y vectores. Un algoritmo de optimización para encontrar el mínimo de una función, por ejemplo, puede usar un vector de primeras derivadas y una matriz de segundas derivadas; y un método para resolver una ecuación diferencial puede usar una matriz con algunas diagonales para calcular las diferencias.
Hay varias formas precisas de definir vectores y matrices, pero generalmente los consideraremos simplemente como conjuntos lineales o rectangulares de números, o escalares, en los que se define un álgebra. A menos que se indique lo contrario, asumiremos que los escalares son números reales. Denotamos tanto el conjunto de números y campo real como ![]() . (El campo es el conjunto de números cerrados bajo una operación binaria de suma y multiplicación). Ocasionalmente tomaremos una perspectiva geométrica para vectores y consideraremos matrices para definir transformaciones geométricas. Sin embargo, en todos los contextos, los elementos de vectores o matrices son números reales (o, más generalmente, miembros de un campo). Cuando los elementos no son miembros de un campo (por ejemplo, nombres o caracteres) usaremos frases más generales, como "listas ordenadas”.
. (El campo es el conjunto de números cerrados bajo una operación binaria de suma y multiplicación). Ocasionalmente tomaremos una perspectiva geométrica para vectores y consideraremos matrices para definir transformaciones geométricas. Sin embargo, en todos los contextos, los elementos de vectores o matrices son números reales (o, más generalmente, miembros de un campo). Cuando los elementos no son miembros de un campo (por ejemplo, nombres o caracteres) usaremos frases más generales, como "listas ordenadas”.
Es muy importante entender que la forma de una expresión matemática y la forma en que se debe evaluar la expresión en la práctica real puede ser muy diferente.
Para un entero positivo n, un vector n (o n-vector) es una n-tupla, un conjunto ordenado (múltiple) o una matriz de n números, llamados elementos o escalares. El número de elementos se llama el orden, o, a veces, la "longitud" del vector. Se puede pensar que un n-vector representa un punto en el espacio de n-dimensional. En esta configuración, la "longitud" del vector también puede significar la distancia euclidiana desde el origen hasta el punto representado por el vector; es decir, la raíz cuadrada de la suma de los cuadrados de los elementos del vector. Esta distancia euclidiana generalmente será lo que queremos decir cuando nos referimos a la longitud de un vector. En general, la "longitud" se mide por una norma o módulo.
Usualmente usamos una letra minúscula para representar un vector, y usamos la misma letra con un solo subíndice para representar un elemento del vector. El primer elemento de un n-vector es el primer elemento 1 y el último es el elemento n-esimo. (Esta afirmación no es una tautología; en algunos sistemas informáticos, el primer elemento de un objeto usado para representar un vector es el elemento 0 del objeto. Esto a veces dificulta la preservación de la relación entre la entidad informática y el objeto que es de interés).
Podemos escribir el n-vector x como forma (2.1) y (2.2) respectivamente como se indican:
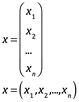
No hacemos distinción entre estas dos notaciones, aunque en algunos contextos pensamos en un vector como una "columna", por lo que la primera notación puede ser más natural. La simplicidad de la segunda notación lo recomienda para uso común.Y esta notación no requiere el símbolo adicional para la transposición que algunas personas usan cuando escriben los elementos de un vector horizontalmente. Dos vectores son iguales sí y solo si son del mismo orden y cada elemento de un vector es igual a el elemento correspondiente del otro.
A primera vista los vectores esencialmente los asociamos a los elementos de un vector con las coordenadas de una geometría cartesiana. Hay otras formas, más abstractas, de desarrollar una teoría de vectores que se denominan "sin coordenadas", pero no seguiremos esos enfoques aquí. Para la mayoría de las aplicaciones en estadística, el enfoque basado en coordenadas es más útil. Pensando en las coordenadas simplemente como números reales, usamos la notación
![]() (2.3)
(2.3)
para denotar el conjunto de n-vectores con elementos reales.
Esta notación refuerza la noción de que las coordenadas de un vector corresponden al producto directo de coordenadas individuales. El producto directo de dos conjuntos se denota como "⊗". Para los conjuntos A y B, es el conjunto de todos las duplas ordenadas
![]()
Por lo tanto:
![]() n veces
n veces
El conjunto consiste de vectores x de la forma de arreglo indexado
![]()
donde los ![]() pertenecen a F, se llaman componentes de x, y F representa ya sea
pertenecen a F, se llaman componentes de x, y F representa ya sea ![]() . Los elementos de
. Los elementos de ![]() son vectores columna. El tamaño
son vectores columna. El tamaño ![]() se deduce que cada escalar es también un vector. Si
se deduce que cada escalar es también un vector. Si ![]() y cada componente de x es no negativo, entonces x es no negativo, es decir, si cada componente de x es positivo, entonces x es positivo.
y cada componente de x es no negativo, entonces x es no negativo, es decir, si cada componente de x es positivo, entonces x es positivo.
Dadas x, y pertenecen a ![]() , y asumimos que
, y asumimos que ![]() y
y ![]() . Entonces a continuación se define la siguiente terminología, si a es un escalar,
. Entonces a continuación se define la siguiente terminología, si a es un escalar,
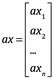
Si ![]() , entonces x y y son linealmente dependientes si existe
, entonces x y y son linealmente dependientes si existe ![]() , de tal manera que x=ay o y=ax. La dependencia lineal para un conjunto de dos o más vectores se define más adelante. Además los vectores se suman componente a componente, es decir, si
, de tal manera que x=ay o y=ax. La dependencia lineal para un conjunto de dos o más vectores se define más adelante. Además los vectores se suman componente a componente, es decir, si ![]() :
:
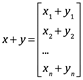
Por lo tanto si ![]() , la combinación lineal
, la combinación lineal ![]() es
es
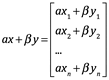
Los vectores columna ![]() son colocados uno al lado de otro forman una matriz.
son colocados uno al lado de otro forman una matriz.
Las matrices son colecciones estructuradas de elementos que corresponden en forma a líneas, rectángulos o sólidos rectangulares. El número de dimensiones de una matriz a menudo se denomina rango de la matriz. Por lo tanto, un vector es una matriz de rango 1, y una matriz es una matriz de rango 2. Un escalar, que puede considerarse como una matriz degenerada, tiene rango 0. Al referirse a objetos de software de computadora, "rango" es generalmente usado en este sentido. Este término proviene de su uso al describir un tensor. Un tensor de rango 0 es un escalar, un tensor de rango 1 es un vector, un tensor de rango 2 es una matriz cuadrada, etc. En nuestro uso que se refiere a matrices cuadradas, requiere que las dimensiones sean iguales, sin embargo, cuando nos referimos al "rango de una matriz", nos referimos al número de dimensiones. En álgebra lineal, este último uso es mucho más común.
Si una matriz es una matriz rectangular o bidimensional, hablamos de las filas y columnas de una matriz. Las filas o columnas pueden considerarse vectores, y a menudo usamos esta equivalencia. Una matriz n × m es una con n filas y m columnas. El número de filas y el número de columnas determinan la forma de la matriz. Tenga en cuenta que la forma son las duplas de índices (n, m). Si el número de filas es el mismo que el número de columnas, se dice que la matriz es cuadrada.
Todas las matrices son bidimensionales en el sentido de "dimensión" utilizado anteriormente. Sin embargo, la palabra "dimensión", cuando se aplica a las matrices, a menudo significa algo diferente, a saber, el número de columnas. Este uso de "dimensión" es común tanto en geometría como en aplicaciones estadísticas tradicionales. Usualmente usamos una letra mayúscula para representar una matriz. Para representar un elemento de la matriz, usualmente usamos la letra minúscula correspondiente con un subíndice para denotar la fila y un segundo subíndice para representar la columna. Si se usa una expresión no trivial para denotar la fila o la columna, separamos los subíndices de fila y columna con una coma.
Aunque los vectores y las matrices son fundamentalmente tipos de objetos bastante diferentes, podemos aportar cierta unidad a nuestra discusión y notación al considerar ocasionalmente que un vector es un "vector columna" y, de alguna manera, es lo mismo que una matriz n × 1. Esto no tiene nada que ver con la forma en que podemos escribir los elementos de un vector. La notación en la ecuación (2.2) es más conveniente que la de la ecuación (2.1) y, por lo tanto, generalmente se usará en este texto, pero su uso no cambia la naturaleza del vector de cualquier manera. Del mismo modo, esto no tiene nada que ver con la forma en que los elementos de un vector o una matriz se almacenan en la computadora. Sin embargo, cuando usamos vectores y matrices en la misma expresión, usamos el símbolo "T" (para "transponer") como superíndice para representar un vector que se está tratando como una matriz 1 × n.
La primera fila es el primer renglón, y la primera columna, la primera de izquierda a derecha. Nuevamente, observamos que las entidades de computadora utilizadas en algunos sistemas para representar matrices y almacenar elementos de matrices como datos de computadora a veces indexan los elementos que comienzan con 0. Además, algunos sistemas usan el primer índice para representar la columna y el segundo índice para indicar la fila. No estamos hablando aquí del orden de almacenamiento “fila mayor” versus “columna mayor”. Más bien, estamos hablando del mecanismo de referirnos a las entidades abstractas de procesamiento, por ejemplo, es una práctica común usar el primer índice para representar la columna y el segundo índice para representar la fila, como en las tablas de cálculo EXCEL.
La matriz A n×m se puede escribir
 (2.4)
(2.4)
También escribimos la matriz A como
![]()
con los índices i y j sobre {1,. . . , n} y {1,. . ., m}, respectivamente. Usamos la notación An×m para referirnos a la matriz A y simultáneamente para indicar que es n×m, y usamos la notación
![]()
para referirse al conjunto de todas las matrices n×m con elementos reales.
Usamos la notación (A)ij para referirnos al elemento en la i-ésima fila y el j-ésima columna de la matriz A; es decir, en la ecuación (2.4), (A)ij = aij.
Dos matrices son iguales sí y solo si tienen la misma forma y cada elemento de una matriz es igual al elemento correspondiente de la otra. Aunque los vectores son vectores de columna y la notación en las ecuaciones (2.1) y (2.2) representa la misma entidad, eso no sería lo mismo para las matrices.
Si x1, ... , xnson escalares (2.5) y la forma (2.6)
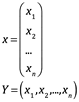
entonces X es una matriz n×1 e Y es una matriz 1×n y X = Y a menos que n = 1. (Y es la transposición de X). Aunque una matriz n × 1 es un tipo diferente de objeto de un vector, podemos tratar X en la ecuación (2.5) o YT en la ecuación (2.6) como un vector cuando sea conveniente hacerlo. Además, aunque una matriz 1 × 1, un vector 1 y un escalar son tipos de objetos fundamentalmente diferentes, trataremos una matriz uno por uno o un vector con un solo elemento como escalar siempre que sea conveniente.
A veces usamos la notación a∗j para corresponder a la j-ésima columna de la matriz A y usamos ai∗ para representar el vector (columna) que corresponde a la i-ésima fila. Usando esa noción, la A matriz n × m en la ecuación (2.4) se puede escribir como las formas (2.7) y (2.8)
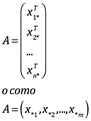
Uno de los usos más importantes de las matrices es como una transformación de un vector por multiplicación de vector por matriz. Dichas transformaciones son lineales (un término que definiremos más adelante). Aunque ocasionalmente se puede distinguir de manera rentable matrices de transformaciones lineales en vectores, para nuestros propósitos actuales no hay ninguna ventaja en hacerlo. A menudo trataremos matrices y transformaciones lineales como equivalentes.
Muchas de las propiedades de los vectores y las matrices que discutimos se mantienen para un número infinito de elementos, pero asumiremos a lo largo de este texto que el número es finito.
2.2 Subvectores y submatrices
A veces nos resulta útil trabajar solo con algunos de los elementos de un vector o matriz. Nos referimos a las matrices respectivas como "subvectores" o "submatrices". También permitimos la reorganización de los elementos por permutaciones de fila o columna y aún consideramos el objeto resultante como un subvector o submatriz. Las dos expresiones (2.7) y (2.8) representan particiones especiales de la matriz A.
2.3 Representación de datos
Antes de que podamos hacer un análisis serio de los datos, los datos deben estar representados en una estructura que sea adecuada para las operaciones del análisis. En casos simples, los datos están representados por una lista de valores escalares. El orden en la lista puede no ser importante, y el análisis puede consistir simplemente en el cálculo de estadísticas resumidas simples. En otros casos, la lista representa una serie temporal de observaciones, y las relaciones de las observaciones entre sí en función de su orden y distancia en la lista son de interés. A menudo, los datos se pueden representar de manera significativa en dos listas que están relacionadas entre sí por las posiciones en las listas. La generalización de esta representación es una matriz bidimensional en la que cada columna corresponde a un tipo particular de datos.
Una consideración importante, por supuesto, es la naturaleza de los elementos individuales de datos. Los datos de observación pueden tener varias formas: medidas cuantitativas, colores, cadenas de texto, etc. Antes de la mayoría de los análisis de datos, deben representarse como números reales. En algunos casos, se pueden representar fácilmente como números reales, aunque puede haber restricciones en la asignación a los reales.
La forma más común de representar datos es mediante el uso de una matriz bidimensional en la que las filas corresponden a unidades de observación ("instancias") y las columnas corresponden a tipos particulares de observaciones ("variables" o "características"). Si los datos corresponden a números reales, esta representación es la matriz de datos X familiar. Gran parte de este texto está dedicado a la teoría de matrices para el análisis de datos en esta forma. Este tipo de matriz, quizás como un vector adjunto, es la estructura básica utilizada en muchos métodos estadísticos familiares, como el análisis de regresión, análisis de componentes principales, análisis de varianza, escalamiento multidimensional, etc.
Existen otros tipos de estructuras basadas en gráficos que son útiles representando datos. Un gráfico es una estructura que consta de dos componentes: un conjunto de puntos, llamados vértices o nodos y un conjunto de pares de puntos, llamados bordes. (Tenga en cuenta que este uso de la palabra "gráfico" puede involucrar redes de grafos es claramente diferente del más común que se refiere a líneas, curvas, barras, etc. para representar datos gráficamente). La frase "teoría de gráficos" a menudo se usa, o se usa en exceso, para enfatizar el significado actual de la palabra. Un gráfico G = (V, E) con vértices V = {v1,. . . , vn} se distingue principalmente por la naturaleza de los elementos de borde (vi, vj) en E. Los gráficos se identifican como gráficos completos, gráficos dirigidos, árboles, etc., dependiendo de E y su relación con V. Se puede usar un árbol para datos que se agregan naturalmente en una jerarquía, como unidad política, subunidad, hogar e individuo. Los árboles también son útiles para representar la agrupación de datos en diferentes niveles de asociación. En este tipo de representación, los elementos de datos individuales son los nodos terminales u "hojas" del árbol.
En otro tipo de representación gráfica que a menudo es útil en la "minería de datos" o "aprendizaje", donde buscamos descubrir relaciones entre objetos, los vértices son los objetos, ya sea unidades de observación o características, y los bordes indican algo en común entre los vértices. Por ejemplo, los vértices pueden ser documentos de texto, y un borde entre dos documentos puede indicar que existe un cierto número de palabras o frases específicas en ambos documentos. A pesar de las diferencias en las formas básicas de representar datos, en forma gráfica.
En el modelado de datos, muchas de las operaciones de matriz estándar utilizadas en el análisis de datos más tradicional se aplican a matrices que surgen naturalmente del gráfico.
 14.36.45.png)
Sin embargo, los datos están representados, ya sea en una matriz o en una red, el análisis de los datos a menudo se facilita mediante el uso de matrices de "asociación". El tipo más familiar de matriz de asociación es quizás una matriz de correlación.
2.4 Operaciones con vectores
Los elementos de los vectores que usaremos a continuación son números reales, es decir, elementos de ![]() . Llamamos elementos de escalares
. Llamamos elementos de escalares ![]() . Las operaciones vectoriales se definen en términos de operaciones en números reales.
. Las operaciones vectoriales se definen en términos de operaciones en números reales.
Se pueden sumar dos vectores si tienen el mismo número de elementos. La suma de dos vectores es el vector cuyos elementos son las sumas de los elementos correspondientes de los vectores que se agregan. Se dice que los vectores con el mismo número de elementos son conformes para la adición. Un vector cuyos elementos son 0 es la identidad aditiva para todos los vectores conformables.
Para no sobrecargar de símbolos, usamos los habituales para las operaciones en los reales para significar las operaciones correspondientes en vectores o matrices cuando se definen las operaciones. Por lo tanto, "+" puede significar la adición de escalares, la adición de vectores conformables o la adición de un escalar a un vector. Este último significado de "+" puede no usarse en muchos tratamientos matemáticos de vectores, pero es consistente con la semántica de los lenguajes de computadora modernos como Fortran, WolframAlpha R y Matlab.
Por la adición de un escalar y un vector, nos referimos a la adición del escalar a cada elemento del vector, lo que resulta en un vector del mismo número de elementos.
Un múltiplo escalar de un vector (es decir, el producto de un número real y un vector) es el vector cuyos elementos son los múltiplos de los elementos correspondientes del vector original. La yuxtaposición de un símbolo para un escalar y un símbolo para un vector indica la multiplicación del escalar con cada elemento del vector, lo que resulta en un vector del mismo número de elementos. La operación básica al trabajar con vectores es la adición de un múltiplo escalar de un vector a otro vector,
z = ax + y, (2.9)
donde a es un escalar y x e y son vectores conformes para la suma. Vista como una operación única con tres operandos, esto se llama operación (axpy) por razones obvias.
La operación axpy es una combinación lineal. Tales combinaciones lineales de vectores son las operaciones básicas en la mayoría de las áreas de álgebra lineal. La composición de las operaciones axpy también es una axpy; es decir, una combinación lineal seguida de otra combinación lineal es una combinación lineal. Además, cualquier combinación lineal puede descomponerse en una secuencia de operaciones axpy. Una combinación lineal especial se llama combinación convexa. Para los vectores x e y, es la combinación
ax + by, (2.10)
donde a, b ≥ 0 y a + b = 1. Se dice que un conjunto de vectores que está cerrado con respecto a las combinaciones convexas es convexo.
2.4.1 Combinaciones lineales e independencia lineal
Si un vector dado puede formarse mediante una combinación lineal de uno o más vectores, se dice que el conjunto de vectores (incluido el dado) es linealmente dependiente; por el contrario, si en un conjunto de vectores no se puede representar un vector como una combinación lineal de ninguno de los otros, se dice que el conjunto de vectores es linealmente independiente. En la ecuación (2.9), por ejemplo, los vectores x, y y z no son linealmente independientes. Sin embargo, es posible que dos de estos vectores sean linealmente independientes.
La independencia lineal es uno de los conceptos más importantes en álgebra lineal. Podemos ver que la definición de un conjunto de vectores linealmente independientes
{v1,. . . , vk} es equivalente a indicar que si
a1v1 + · · · akvk = 0,
entonces a1 = ··· = ak = 0. Si el conjunto de vectores {v1,. . . , vk} no es linealmente independiente, entonces es posible seleccionar un subconjunto máximo linealmente independiente; es decir, un subconjunto de {v1,. . . , vk} que es linealmente independiente y tiene la máxima cardinalidad. Hacemos esto seleccionando un vector arbitrario, vi1, y luego buscando un vector que sea independiente de vi1. Si no hay ninguno en el conjunto que sea linealmente independiente de vi1, entonces un subconjunto máximo linealmente independiente es solo el singleton, porque todos los vectores deben ser una combinación lineal de un solo vector (es decir, un múltiplo escalar de ese vector). Si hay un vector que es linealmente independiente de vi1, digamos vi2, luego buscamos un vector en el conjunto restante que sea independiente de vi1 y vi2. Si uno no existe, entonces {vi1, vi2} es un subconjunto máximo porque cualquier otro vector puede representarse en términos de estos dos y, por lo tanto, dentro de cualquier subconjunto de tres vectores, uno puede representarse en términos de los otros dos. Por lo tanto, vemos cómo formar un subconjunto máximo linealmente independiente, y vemos que la cardinalidad máxima de cualquier subconjunto de vectores linealmente independientes es única, sin embargo, se forman.
Es fácil ver que el número máximo de n-vectores que pueden formar un conjunto que es linealmente independiente es n. (Podemos ver esto asumiendo n-vectores linealmente independientes y luego, para cualquier (n + 1) vector, mostrando que es una combinación lineal de los demás al construirlo uno por uno a partir de combinaciones lineales de dos de los dados linealmente vectores independientes.
Las propiedades de un conjunto de vectores generalmente son invariables para una permutación de los elementos de los vectores si se aplica la misma permutación a todos los vectores del conjunto. En particular, si un conjunto de vectores es linealmente independiente, el conjunto permanece linealmente independiente si los elementos de cada vector se permutan de la misma manera.
Si los elementos de cada vector en un conjunto de vectores se separan en subvectores, la independencia lineal de cualquier conjunto de subvectores correspondientes implica independencia lineal de los vectores completos. Para establecer esto con mayor precisión para un conjunto de tres n-vectores, supongamos que x = (x1,..., xn), y = (y1,..., yn) y z = (z1,..., zn )
Ahora dejemos {i1,. . . , ik} ⊆ {1,. . . , n}, y forman los k-vectores
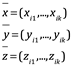
Entonces la independencia lineal de ![]() ,
, ![]() y
y ![]() implica independencia lineal de x, y y z. Esto se puede mostrar directamente de la definición de independencia lineal.
implica independencia lineal de x, y y z. Esto se puede mostrar directamente de la definición de independencia lineal.
Sea V un conjunto de n-vectores de manera que cualquier combinación lineal de los vectores en V también esté en V. Tal conjunto junto con el álgebra vectorial habitual se llama espacio vectorial. Un espacio vectorial es un espacio lineal y necesariamente incluye la identidad aditiva (el vector cero). (Para ver esto, en la operación axpy, deje a = −1 e y = x.) Un espacio vectorial es necesariamente convexo.
El conjunto que consiste solo en la identidad aditiva, junto con la operación axpy, es un espacio vectorial. Se llama el "espacio vectorial nulo". Algunas personas definen el "espacio vectorial" de una manera que lo excluye, porque sus propiedades no se ajustan a muchas declaraciones generales que podemos hacer sobre otros espacios vectoriales.
2.4.2 Espacio vectorial y espacio de vectores
Sea V un conjunto de n-vectores de manera que cualquier combinación lineal de los vectores en V también esté en V. Tal conjunto junto con el álgebra vectorial habitual se llama espacio vectorial. Un espacio vectorial es un espacio lineal y necesariamente incluye la identidad aditiva (el vector cero). (Para ver esto, en la operación axpy, deje a=−1 y y= x.) Un espacio vectorial es necesariamente convexo.
El conjunto que consiste solo en la identidad aditiva, junto con la operación axpy, es un espacio vectorial. Se llama "espacio vectorial nulo". Algunas personas definen el "espacio vectorial" de una manera que lo excluye, porque sus propiedades no se ajustan a muchas declaraciones generales que podemos hacer sobre otros espacios vectoriales.
El "álgebra habitual" es un álgebra lineal que consta de dos operaciones: suma de vectores y multiplicación vectorial de tiempos escalares, que son las dos operaciones que comprenden una axpy. Tiene cierre del espacio bajo la combinación de esas operaciones, conmutatividad y asociatividad de suma, una identidad aditiva e inversas, una identidad multiplicativa, distribución de multiplicación sobre la suma de vectores y la suma escalar, y la asociatividad de multiplicación escalar y multiplicación vectorial de tiempos escalares .
Un espacio vectorial también puede estar compuesto de otros objetos, como matrices, junto con sus operaciones apropiadas. La característica clave de un espacio vectorial es un álgebra lineal.
Generalmente usamos una fuente caligráfica para denotar un espacio vectorial; V o W, por ejemplo. A menudo, sin embargo, pensamos en el espacio vectorial simplemente en términos del conjunto de vectores sobre el que está construido y lo denotamos con una letra mayúscula ordinaria; V o W, por ejemplo. Un espacio vectorial es una estructura algebraica que consiste en un conjunto junto con la operación axpy, con la restricción de que el conjunto esté cerrado bajo la operación. Para indicar que es una estructura, en lugar de solo un conjunto, podemos escribir
![]()
donde V es solo el conjunto y o denota la operación axpy, o una operación lineal similar bajo la cual se cierra el conjunto.
La característica esencial de los vectores es que si los añadimos o tomamos múltiplos escalares de ellos, obtenemos otro vector; por lo tanto, una combinación lineal de vectores es de nuevo un vector. La teoría general de los espacios vectoriales se basa en esta simple idea, con esto en mente podemos estudiar espacios abstractos. El hecho de que la teoría de espacios vectoriales sea tan ampliamente aplicable hace que el uso del tipo abstracto sea incómoda. Escribiéremos ![]() y V pertenece a un campo. El espacio vectorial consta de un conjunto V de vectores y un campo de escalares F, dados por
y V pertenece a un campo. El espacio vectorial consta de un conjunto V de vectores y un campo de escalares F, dados por ![]() . Los vectores forman un grupo abeliano con respecto a una operación que se llama adición y se denota por +. Los escalares nos permiten un múltiplo escalar de un vector; por lo tanto, a cada escalar
. Los vectores forman un grupo abeliano con respecto a una operación que se llama adición y se denota por +. Los escalares nos permiten un múltiplo escalar de un vector; por lo tanto, a cada escalar ![]() y a cada vector v, podemos asociar un vector
y a cada vector v, podemos asociar un vector ![]() . Como consecuencia de estos supuestos, dado escalares
. Como consecuencia de estos supuestos, dado escalares ![]() y
y ![]() esto podemos decir que es una combinación lineal
esto podemos decir que es una combinación lineal ![]() y esto también es un vector.
y esto también es un vector.
2.4.2.1 Conjuntos generadores
Dado un conjunto G de vectores del mismo orden, se puede formar un espacio vectorial a partir del conjunto G junto con todos los vectores que resultan de la operación axpy aplicada a todas las combinaciones de vectores en G y todos los valores del número real a; es decir, para todos los vi, vj ∈ G y todos los reales a,
![]()
Este conjunto junto con la operación axpy en sí es un espacio vectorial. Se llama el espacio generado por G. Denotamos este espacio como
span (G).
2.4.2.2 El orden y la dimensión de un espacio vectorial
El espacio vectorial que consiste en todos los n-vectores con elementos reales se denota ![]() . (Como se mencionó anteriormente, la notación
. (Como se mencionó anteriormente, la notación ![]() también puede referirse solo al conjunto de n-vectores con elementos reales; es decir, al conjunto sobre el que se define el espacio vectorial).
también puede referirse solo al conjunto de n-vectores con elementos reales; es decir, al conjunto sobre el que se define el espacio vectorial).
La dimensión de un espacio vectorial es el número máximo de vectores linealmente independientes en el espacio vectorial (o llamada base). Denotamos la dimensión por la cual es un mapeo ![]() →
→ ![]() (donde
(donde ![]() denota los enteros positivos).
denota los enteros positivos).
El orden de un espacio vectorial es el orden de los vectores en el espacio. Como el número máximo de n-vectores que pueden formar un conjunto linealmente independiente es n, como mostramos anteriormente, el orden de un espacio vectorial es mayor o igual que la dimensión del espacio vectorial.
Tanto el orden como la dimensión de ![]() son n. Un conjunto de m vectores linealmente independientes con n elementos reales puede generar un espacio vectorial dentro de
son n. Un conjunto de m vectores linealmente independientes con n elementos reales puede generar un espacio vectorial dentro de ![]() de orden n y dimensión m.
de orden n y dimensión m.
También podemos usar la frase dimensión de un vector para significar la dimensión del espacio vectorial del cual el vector es un elemento. Este término es ambiguo, pero su significado es claro en contextos específicos, como la reducción de dimensiones, que discutiremos más adelante.
2.4.2.3 Espacios vectoriales con un número infinito de dimensiones
Es posible que ningún conjunto finito de vectores abarque un espacio vectorial dado. En ese caso, se dice que el espacio vectorial es de dimensión infinita. Muchas de las propiedades de los espacios vectoriales que discutimos son válidas para aquellos con un número infinito de dimensiones; pero no todos lo hacen, como la equivalencia de las normas.
Sin embargo, a lo largo de este texto, a menos que indiquemos lo contrario, asumimos que los espacios vectoriales tienen un número finito de dimensiones.
2.4.2.4 Espacios de vectores esencialmente disjuntos
Si el único elemento en común entre dos espacios vectoriales V y W es la identidad aditiva, se dice que los espacios son esencialmente disjuntos. Esencialmente, los espacios vectoriales disjuntos necesariamente tienen el mismo orden.
Si los espacios vectoriales V y W son esencialmente disjuntos, está claro que cualquier elemento en V (excepto la identidad aditiva) es linealmente independiente de cualquier conjunto de elementos en W.
2.4.2.5 Algunos vectores especiales: notación
Denotamos la identidad aditiva en un espacio vectorial de orden n por 0n o, a veces solo por 0. Este es el vector que consiste en todos los ceros:
![]() Ec. (2.11)
Ec. (2.11)
Llamamos a esto el vector cero, o el vector nulo. (Un vector ![]() se denomina "vector no nulo"). Este vector en sí mismo a veces se denomina espacio vectorial nulo. No es un espacio vectorial en el sentido habitual; tendría dimensión 0. (Todas las combinaciones lineales son iguales).
se denomina "vector no nulo"). Este vector en sí mismo a veces se denomina espacio vectorial nulo. No es un espacio vectorial en el sentido habitual; tendría dimensión 0. (Todas las combinaciones lineales son iguales).
Del mismo modo, denotamos el vector que consiste en todos por 1n o, a veces solo por 1:
![]() Ec. (2.12)
Ec. (2.12)
Llamamos a este el vector uno y también el "vector sumador". Este vector y todos sus múltiplos escalares son espacios vectoriales con dimensión 1. (Esto es cierto para cualquier vector único distinto de cero; todas las combinaciones lineales son simplemente múltiplos escalares). Si 0 y 1 sin un subíndice representan vectores o escalares, por lo general, está claro en el contexto.
El vector cero y el vector uno son instancias de vectores constantes; es decir, vectores todos cuyos elementos son iguales. En algunos casos, podemos abusar ligeramente de la notación, como lo hemos hecho con “0” y “1” arriba, y usar un solo símbolo para denotar tanto un escalar como un vector cuyos elementos son tan constantes; por ejemplo, si "c" denota una constante escalar, también podemos referirnos al vector cuyos elementos son c como "c". Estas convenciones de notación rara vez dan lugar a alguna ambigüedad. También permiten otra interpretación de la definición de adición de un escalar a un vector que mencionamos al comienzo.
El vector unitario i-ésimo, denotado por ei, tiene un 1 en la posición i-ésima y 0s en todas las demás posiciones:
![]() Ec. (2.13)
Ec. (2.13)
Otro vector útil es el vector de signo, que se forma a partir de signos de los elementos de un vector dado. Se denota por "signo (·)" y para x = (x1,..., xn) se define por
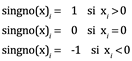 Ec.(2.14)
Ec.(2.14)
2.4.2.6 Relaciones ordinales entre vectores
Hay varias formas posibles de formar un orden de clasificación de vectores del mismo orden, pero ningún orden completo es completamente satisfactorio. (Observe la desafortunada sobrecarga de las palabras "orden" y "ordenar" aquí.) Si x e y son vectores del mismo orden y para los elementos correspondientes xi> yi, decimos que x es mayor que y y escribimos
X>y Ec. (2.15)
En particular, si todos los elementos de x son positivos, escribimos x> 0.
Si x e y son vectores del mismo orden y para los elementos correspondientes xi ≥ yi, decimos que x es mayor o igual que y y escribimos
![]() Ec. (2.16)
Ec. (2.16)
C
Las operaciones ordinarias de subconjunto, intersección, unión, suma directa y producto directo para conjuntos tienen análogos para espacios vectoriales, y usamos algo de la misma notación para referirnos a espacios vectoriales que usamos para referirnos a conjuntos. Las operaciones del conjunto se realizan en los conjuntos individuales para producir un conjunto de vectores, y el espacio vectorial resultante es el espacio generado por ese conjunto de vectores.
Desafortunadamente, hay muchas inconsistencias en la terminología utilizada en la literatura con respecto a las operaciones en espacios vectoriales. Cuando usamos un término y/o símbolo, como “unión” o “∪”, para una estructura como un espacio vectorial, lo usamos en referencia a la estructura. Por ejemplo, si V = (V, ?) y W = (W,?) son espacios vectoriales, entonces V ∪ U es la unión ordinaria de los conjuntos; sin embargo, V ∪ W es la unión de los espacios vectoriales, y no es necesariamente lo mismo que (U ∪ W, ?), que ni siquiera puede ser un espacio vectorial. Ocasionalmente, en la siguiente discusión, intentaremos señalar variantes comunes en el uso.
La convención que seguimos permite que las relaciones bien conocidas entre las operaciones de conjuntos comunes se mantengan para las operaciones correspondientes en espacios vectoriales; por ejemplo, si V y W son espacios vectoriales, V ⊆ V∪W, al igual que para los conjuntos V y W.
Las propiedades de los espacios vectoriales se prueban de la misma manera que se prueban las propiedades de los conjuntos, después de requerir primero que la operación axpy tenga el mismo significado en los diferentes espacios vectoriales. Por ejemplo, para demostrar que un espacio vectorial es un subespacio de otro, mostramos que cualquier vector dado en el primer espacio vectorial está necesariamente en el segundo. Para demostrar que dos espacios vectoriales son iguales, mostramos que cada uno es un subespacio del otro. Algunas propiedades de los espacios vectoriales y subespacios se pueden mostrar más fácilmente utilizando "conjuntos básicos" para los espacios.
Tenga en cuenta que si (V, ?) y (W, ?) son espacios vectoriales del mismo orden y U es un conjunto formado por una operación en V y W, entonces (U, ?) puede no ser un espacio vectorial porque es no cerrado bajo la operación axpy, ?. Algunas veces nos referimos a un conjunto de vectores del mismo orden junto con el operador axpy (ya sea que el conjunto esté cerrado o no con respecto al operador) como un "espacio de vectores" (en lugar de un "espacio vectorial").
2.4.2.7 Subespacio
Dado un espacio vectorial V = (V, ?), si W es cualquier subconjunto de V, entonces el espacio vectorial W generado por W, es decir, span(W), se dice que es un subespacio de V, y denotamos esto relación por W ⊆V.
Si W ⊆ V y W = V, entonces se dice que W es un subespacio apropiado de V. Si W = V, entonces W ⊆V y V ⊆W, y lo contrario también es cierto.
El número máximo de vectores linealmente independientes en el subespacio no puede ser mayor que el número máximo de vectores linealmente independientes en el espacio original; es decir, si W ⊆V, entonces
![]() Ec. (2.17)
Ec. (2.17)
Si W es un subespacio apropiado de V, entonces dim (W) <dim (V).
2.4.2.8 Intersecciones de espacios vectoriales
Para dos espacios vectoriales V y W del mismo orden con vectores formados a partir del mismo campo, definimos su intersección, denotada por V ∩ W , como el conjunto de vectores que consiste en la intersección de los conjuntos en los espacios vectoriales individuales junto con la operación axpy.
La intersección de dos espacios vectoriales del mismo orden que no son esencialmente disjuntos es un espacio vectorial, como podemos ver dejando x e y ser cualquier vector en la intersección U = V ∩ W, y mostrando, para cualquier número real a, que ax + y ∈ U. Esto es fácil porque tanto x como y deben estar en V y W.
Tenga en cuenta que si V y W son esencialmente disjuntos, entonces V ∩W = (0, ?), que, como hemos dicho, no es un espacio vectorial en el sentido habitual.
También tenga en cuenta que dim (V ∩W) ≤ min (dim (V), dim (W))
2.4.2.9 Uniones y sumas directas de espacios vectoriales
Dados dos espacios vectoriales V y W del mismo orden, definimos su unión, denotada por V ∪ W, como el espacio vectorial generado por la unión de los conjuntos en los espacios vectoriales individuales junto con la operación axpy (recuerde que axpy se refiere a la operación de cerradura de que toda álgebra debe cumplir bajo una operación binaria). Si V = (V, ?) y W = (W, ?), este es el espacio vectorial generado por el conjunto de vectores V ∪ W; es decir,
V ∪ W = span (V∪W). Ec. (2.18)
La unión de los conjuntos de vectores en dos espacios vectoriales no puede cerrarse bajo la operación axpy, pero la unión de espacios vectoriales es un espacio vectorial por definición.
El espacio vectorial generado por la unión de los conjuntos en los espacios vectoriales individuales es fácil de formar. Dado que (V, ?) y (W, ?) son espacios vectoriales (por lo que para cualquier vector x en V o W, ax está en ese conjunto), todo lo que necesitamos hacer es incluir todas las sumas simples de los vectores del individuo conjuntos, es decir,
V ∪W = {v + w, s.t. v ∈ V, w ∈W}. Ec. (2.19)
Es fácil ver que este es un espacio vectorial mostrando que está cerrado con respecto a axpy. (Como arriba, mostramos que para cualquier x e y en V ∪ W y para cualquier número real a, ax + y está en V ∪W).
A pesar de la posible confusión con otros usos de la notación, a menudo uso la notación V ⊕ W porque apunta directamente a la buena construcción de la ecuación (2.19). Para ser claros: en la medida en que usemos "suma directa" y "⊕" para los espacios vectoriales V y W, me referiré a la suma directa
V ⊕W ≡ V ∪ W, Ec. (2.20)
como se definió anteriormente.
Tenga en cuenta que
dim (V ⊕W) = dim (V) + dim (W) - dim (V ∩W) Ec. (2.21)
Por lo tanto
dim (V ⊕W) ≥ max (dim (V), dim (W))
y
dim (V ⊕W) ≤ dim (V) + dim (W)
2.4.2.10 Descomposición de suma directa de un espacio vectorial
En algunas aplicaciones, dado un espacio vectorial V, es de interés encontrar espacios vectoriales esencialmente disjuntos V1,. . . , Vn tal que
V = V1 ⊕ · · · ⊕Vn.
Esto se llama una descomposición de suma directa de V. (Como mencionamos anteriormente, algunos autores no usan “suma directa” como nosotros usamos el término en este contexto porque las matrices individuales son esencialmente disjuntas debido a sus dimesiones). Está claro que si V1,. . . , Vn es una descomposición de suma directa de V, entonces...
![]() Ec. (2.22)
Ec. (2.22)
Una colección de espacios vectoriales esencialmente disjuntos V1,. . . ,Vntal que V = V1⊕ · · · ⊕Vn se dice que es complementario con respecto a V.
Una propiedad importante de una descomposición de suma directa es que permite una representación única de un vector en el espacio descompuesto en términos de una suma de vectores de los espacios esencialmente disjuntos individuales; es decir, si
V = V1⊕ · · · ⊕Vn es una descomposición de suma directa de V y v ∈ V, entonces existen vectores únicos vi ∈ Vi tales que
v = v1 + · · · + vn Ec. (2.23)
Probaremos esto para el caso n = 2. Esto es una pérdida, porque los espacios adicionales en la descomposición no agregan nada diferente.
Dada la descomposición de suma directa V = V1⊕ V2, sea v cualquier vector en V. Debido a que V1⊕ V2 se puede formar como en la ecuación (2.19), existen vectores v1∈V1 y v2∈ V2 tales que v = v1 + v2. Ahora todo lo que tenemos que hacer es demostrar que son únicos.
Deje que u1∈ V1 y u2∈ V2 sean tales que v = u1 + u2. Ahora tenemos (v − u1) ∈V2 y (v - v1) ∈ V2; por lo tanto (v1 - u1) ∈ V2. Sin embargo, desde v1, u1∈ V1, (v1 - u1) ∈ V1. Dado que V1 y V2 son esencialmente disjuntos, y (v1 - u1) está en ambos, debe ser el caso de que (v1 - u1) = 0 o u1 = v1. De igual manera, nosotros muestra que u2=v2; por lo tanto, la representación v = v1 + v2 es única.
Un hecho importante es que para cualquier espacio vectorial V con dimensión 2 o mayor, existe una descomposición de suma directa; es decir, existen espacios vectoriales esencialmente disjuntos V1 y V2 tales que V = V1⊕ V2.
Esto se muestra fácilmente eligiendo primero un subespacio apropiado V1de V y luego construyendo un subespacio esencialmente disjunto V2 tal que V = V1⊕ V2.
2.4.2.11 Productos directos de espacios vectoriales y reducción de dimensiones
Las operaciones de establecimiento en espacios vectoriales que hemos mencionado hasta ahora requieren que los espacios vectoriales sean de un orden fijo. A veces, en las aplicaciones, es útil tratar con espacios vectoriales de diferentes órdenes.
El producto directo del espacio vectorial V de orden n y el espacio vectorial W de orden m es el espacio vectorial de orden n + m en el conjunto de vectores
{(v1,..., vn, w1,..., wm) o, (v1,..., vn) ∈ V, (w1,..., wm) ∈ W}, Ec. (2.24)
junto con el operador axpy definido como el mismo operador en V y W aplicado por separado a los primeros n y los últimos m elementos. El producto directo de V y W se denota por V ⊗ W .
Observe que, si bien la operación de suma directa es conmutativa, el producto directo no es conmutativo en general.
Los vectores en V y W a veces se denominan "subvectores" de los vectores en V ⊗ W. Estos subvectores están relacionados con las proyecciones.
Podemos ver que el producto directo es un espacio vectorial usando el mismo método que el anterior al mostrar que está cerrado bajo la operación axpy.
Tenga en cuenta que
dim (V ⊗W) = dim (V) + dim (W) Ec. (2.25)
Tenga en cuenta que para enteros 0 <p <n,
![]() Ec. (2.26)
Ec. (2.26)
donde las operaciones en el espacio ![]() son las mismas que en los espacios de vector componente con el significado para ajustarse al orden mayor de los vectores en
son las mismas que en los espacios de vector componente con el significado para ajustarse al orden mayor de los vectores en ![]() . (Recuerde que
. (Recuerde que ![]() representa la estructura algebraica que consiste en el conjunto de n-tuplas de números reales más el operador especial axpy).
representa la estructura algebraica que consiste en el conjunto de n-tuplas de números reales más el operador especial axpy).
En aplicaciones estadísticas, a menudo queremos hacer una "reducción de dimensiones". Esto significa encontrar un número menor de coordenadas que cubran las regiones relevantes de un espacio de mayor dimensión. En otras palabras, estamos interesados en encontrar un espacio vectorial de dimensión inferior en el que un conjunto dado de vectores en un espacio vectorial de dimensión superior se pueda aproximar por vectores en el espacio dimensional inferior. Para un conjunto dado de vectores de la forma x = (x1,..., xn) buscamos un conjunto de vectores de la forma
z = (z1,..., zp) que casi "cubren el mismo espacio". (La transformación de x a z se llama proyección).
2.4.3 Conjuntos básicos para espacios vectoriales
Si cada vector en el espacio vectorial V puede expresarse como una combinación lineal de los vectores en algún conjunto G, entonces se dice que G es un conjunto generador o un conjunto de expansión de V. El número de vectores en un conjunto generador es al menos igual a la dimensión del espacio vectorial.
Si todas las combinaciones lineales de los elementos de G están en V, el espacio vectorial es el espacio generado por G y se denota por V(G) o por span(G). Usaremos cualquier notación indistintamente:
V (G) ≡ span (G) Ec. (2.27)
Tenga en cuenta que G también es un conjunto generador o de expansión para W donde W ⊆ span(G).
Una base para un espacio vectorial es un conjunto de vectores linealmente independientes que generan o abarcan el espacio. Para cualquier espacio vectorial, un conjunto generador que consta del número mínimo de vectores de cualquier conjunto generador para ese espacio es un conjunto base para el espacio. Un conjunto de bases obviamente no es único.
Tenga en cuenta que la independencia lineal implica que un conjunto base no puede contener el vector 0.
Un hecho importante es
• La representación de un vector dado en términos de un conjunto base dado es única.
Para ver esto, deje {v1,. . . , vk} ser la base de un espacio vectorial que incluye el vector x, y dejar
x = c1v1 + · · · ckvk
Ahora supongamos
x = b1v1 + · · · bkvk
para que tengamos
0 = (c1 - b1) v1 + · · · + (ck - bk) vk
Desde {v1,. . . , vk} son independientes, la única forma en que esto es posible es si ci=bi para cada i.
Un hecho relacionado es que si {v1,. . . , vk} es una base para un espacio vectorial de orden n que incluye el vector x y x = c1v1 + · · · ckvk, entonces x =0n si y solo si ci=0 para cada i.
Para cualquier espacio vectorial, el orden de los vectores en un conjunto base es el mismo que el orden del espacio vectorial.
Debido a que los vectores en un conjunto base son independientes, el número de vectores en un conjunto base es el mismo que la dimensión del espacio vectorial; es decir, si B es un conjunto básico del espacio vectorial V, entonces
tenue (V) = # (B). Ec. (2.28)
Una base simple establecida para el espacio vectorial ![]() es el conjunto de vectores unitarios {e1,. . . , en}.
es el conjunto de vectores unitarios {e1,. . . , en}.
2.4.3.1 Propiedades de conjuntos básicos de subespacios vectoriales
Hay varios hechos interesantes sobre conjuntos de bases para espacios vectoriales y varias combinaciones de los espacios vectoriales. Las verificaciones de estos hechos siguen argumentos similares.
• Si B1 es un conjunto de bases para V1, B2 es un conjunto de bases para V2, y V1 y V2 son esencialmente disjuntos, entonces B1∩ B2 = ∅. Este hecho se ve fácilmente asumiendo lo contrario; es decir, suponga que b ∈ B1∩ B2. (Tenga en cuenta que b no puede ser el vector 0). Sin embargo, esto implica que b está en V1 y V2, lo que contradice la hipótesis de que son esencialmente disjuntos.
• Si B es una base establecida para V y V1⊆ V, entonces existe B1, con B1⊆ B, de modo que B1 es una base establecida para V1.
• Si B1 es un conjunto base para V1 y B2es un conjunto base para V2, entonces B1∪B2 es un conjunto generador para V1⊕V2. (Esto se ve fácilmente en la definición de ⊕ porque cualquier vector en V1⊕V2 puede representarse como una combinación lineal de vectores en B1 más una combinación lineal de vectores en B2).
• Si V1 y V2 son esencialmente disjuntos, B1 es un conjunto de bases para V1 y B2 es un conjunto de bases para V2, entonces B1∪ B2 es un conjunto de bases para V=V1⊕V2. Este es el caso de que V1⊕ V2 es una descomposición de suma directa de V.
• Suponga que V1 es un espacio vectorial real de orden n1 (es decir, es un subespacio de ![]() ) y B1 es un conjunto base para V1. Ahora dejemos que V2 sea un espacio vectorial real de orden n2y B2 sea una base establecida para V2. Para cada vector b1 en B1 forma el vector
) y B1 es un conjunto base para V1. Ahora dejemos que V2 sea un espacio vectorial real de orden n2y B2 sea una base establecida para V2. Para cada vector b1 en B1 forma el vector
![]()
donde hay n2 0s,
y que ![]() sea el conjunto de todos esos vectores. (El orden de cada
sea el conjunto de todos esos vectores. (El orden de cada ![]() ∈
∈ ![]() es
es
n1 + n2). Del mismo modo, para cada vector b2 en B2 forma el vector
![]() donde hay n1 0s
donde hay n1 0s
y deja que B2 sea el conjunto de todos esos vectores. Entonces B1∪ B2 es una base para V1⊗V2.
2.5 Productos internos
Una operación útil en dos vectores x e y del mismo orden es el producto interno, que denotamos por
![]()
definimos como
![]()
donde ![]() representa el complejo conjugado de z; es decir, si z = a + bi, entonces
representa el complejo conjugado de z; es decir, si z = a + bi, entonces
![]() =a−bi. En general, a lo largo de este libro, a menos que se indique lo contrario, supongamos que estamos trabajando con números reales y, por lo tanto,
=a−bi. En general, a lo largo de este libro, a menos que se indique lo contrario, supongamos que estamos trabajando con números reales y, por lo tanto, ![]() = z. La mayoría de las declaraciones mantendrán si los números son reales o complejos. Cuando las declaraciones solo son válidas para reales, generalmente incluiré la excepción en la declaración. Las principales diferencias tienen que ver con los productos internos y una propiedad importante definida en términos de un producto interno, llamada ortogonalidad. En el caso de vectores con elementos reales, tenemos
= z. La mayoría de las declaraciones mantendrán si los números son reales o complejos. Cuando las declaraciones solo son válidas para reales, generalmente incluiré la excepción en la declaración. Las principales diferencias tienen que ver con los productos internos y una propiedad importante definida en términos de un producto interno, llamada ortogonalidad. En el caso de vectores con elementos reales, tenemos
En ese caso (que es lo que generalmente asumimos a lo largo de este libro), el producto interno es un mapeo
![]() Ec. (2.29)
Ec. (2.29)
El producto interno también se llama producto de punto o producto escalar.
![]()
El producto punto es en realidad un tipo especial de producto interno, y existe cierta ambigüedad en la terminología. El producto de punto es el producto interno más utilizado en las aplicaciones que consideramos, por lo que utilizaremos los términos como sinónimos.
El producto interno también a veces se escribe como ![]() , de ahí el nombre del producto punto. Otra notación para el producto interno para vectores reales es xTy, y veremos más adelante que esta notación es natural en el contexto de la multiplicación de matrices. Entonces, para vectores reales, tenemos las anotaciones equivalentes
, de ahí el nombre del producto punto. Otra notación para el producto interno para vectores reales es xTy, y veremos más adelante que esta notación es natural en el contexto de la multiplicación de matrices. Entonces, para vectores reales, tenemos las anotaciones equivalentes
![]() Ec. (2.30)
Ec. (2.30)
(Mencionaré una notación más que es equivalente a vectores reales. Esta es la notación de "bra-ket“ originada por Paul Dirac, y todavía se usa en ciertas áreas de aplicación. Dirac se refirió a xT como "bra x", y lo denotó como ![]() . Se refirió a un vector ordinario y como "ket y", y lo denotó como
. Se refirió a un vector ordinario y como "ket y", y lo denotó como ![]() . Luego denotó el producto interno de los vectores como
. Luego denotó el producto interno de los vectores como ![]() , u omitiendo una barra vertical, como
, u omitiendo una barra vertical, como ![]() )
)
En general, el producto interno es una asignación de un espacio vectorial real V a ![]() que tiene las siguientes propiedades:
que tiene las siguientes propiedades:
1. No negatividad y mapeo de la identidad aditiva:
si ![]() , entonces
, entonces ![]() y
y ![]() .
.
2. La conmutatividad:
![]() .
.
3. Factorización de la multiplicación escalar en productos punto:
![]() , y para real a.
, y para real a.
4. Relación de la adición de vectores a la adición de productos de punto:
![]() .
.
De hecho, estas propiedades definen un producto interno para objetos matemáticos para los que se define una suma, una identidad aditiva y una multiplicación por un escalar. Observe que la operación definida en la ecuación ![]() no es un producto interno para vectores sobre el campo complejo porque, si x es complejo, podemos tener
no es un producto interno para vectores sobre el campo complejo porque, si x es complejo, podemos tener ![]() cuando
cuando ![]() . Un espacio vectorial junto con un El producto interno se llama espacio interno del producto.
. Un espacio vectorial junto con un El producto interno se llama espacio interno del producto.
Los productos internos también se definen para las matrices. Debemos señalar de paso que hay dos tipos diferentes de multiplicación utilizados en la propiedad 3. La primera multiplicación es la multiplicación escalar, es decir,
una operación de ![]() a
a ![]() , que hemos definido anteriormente, y la segunda multiplicación es la multiplicación ordinaria en IR, es decir, una operación de
, que hemos definido anteriormente, y la segunda multiplicación es la multiplicación ordinaria en IR, es decir, una operación de ![]() para
para ![]() . También hay dos tipos diferentes de adición utilizados en la propiedad 4. La primera adición es la adición de vectores, definida anteriormente, y la segunda adición es la adición ordinaria en
. También hay dos tipos diferentes de adición utilizados en la propiedad 4. La primera adición es la adición de vectores, definida anteriormente, y la segunda adición es la adición ordinaria en ![]() . El producto punto puede revelar relaciones fundamentales entre los dos vectores, como veremos más adelante. Una propiedad útil de los productos internos es la desigualdad de Cauchy-Schwarz:
. El producto punto puede revelar relaciones fundamentales entre los dos vectores, como veremos más adelante. Una propiedad útil de los productos internos es la desigualdad de Cauchy-Schwarz:
![]() Ec. (2.31)
Ec. (2.31)
Esta relación también se denomina a veces desigualdad de Cauchy-Bunyakovskii-Schwarz. (Augustin-Louis Cauchy dio la desigualdad para el tipo de productos internos discretos que estamos considerando aquí, y Viktor Bunyakovskii y Hermann Schwarz lo extendieron independientemente a productos internos más generales, definidos en funciones). La desigualdad es fácil de ver, observando primero que por cada número real t,
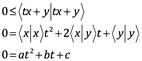
donde las constantes a, b y c corresponden a los productos punto en la ecuación anterior. Esta cuadrática en t no puede tener dos raíces reales distintas. Por lo tanto, el discriminante, b2 - 4ac, debe ser menor o igual que cero; es decir,
![]()
Al sustituir y tomar raíces cuadradas, obtenemos la desigualdad de Cauchy-Schwarz. También es claro a partir de esta prueba que la igualdad se cumple solo si x = 0 o si y=rx, para algún r escalar.
Dos vectores x e y tal que x, y=0 se dice que son ortogonales. Este término tiene un significado tan intuitivo que podemos usarlo antes de una definición y estudio cuidadosos, por lo que solo lo presentamos aquí.
Si recogemos cualquier libro sobre mecánica cuántica, seguro que encontrarás muchas funciones de onda y las soluciones a la ecuación de Schrödinger. Pero el lenguaje utilizado para escribir esas funciones y, las técnicas matemáticas utilizadas para analizarlas, están arraigadas en el mundo de los vectores. En sus estudios de secundaria y bachillerato se familiariza con vectores dirección, unitarios, posición, perpendiculares, producto interno y producto cruz. Pero este conocimiento es necesario extenderlo más profundamente dentro del álgebra lineal. Aspectos necesarios para la química física de la mecánica cuántica.
Cuando aprendió por primera vez en la educación secundaria sobre vectores, probablemente pensó en un vector como una entidad que tiene magnitud (longitud en el mundo material) y dirección (ángulo de algún conjunto de ejes que describen las dimensiones del espacio). También, puede que haber aprendido a escribir un vector empleando vectores unitarios para los ejes dimensionales; el vector se escribe con una letra y una flecha encima y se expande en su forma polinomial:
![]() (2.32)
(2.32)
 17.21.32.png)
Fig. 2.1 Vector cartesiano en sus componentes y vectores unitarios.
En la expansión Ax,Ay,Az son los componentes del vector ![]() y
y ![]() son vectores bases indicadores de la dirección del sistema de coordinadas sobre el que se expande el vector
son vectores bases indicadores de la dirección del sistema de coordinadas sobre el que se expande el vector ![]() . En este caso, se trata de un sistema de coordenadas Cartesiano x,y,z. Es importante comprender que el vector
. En este caso, se trata de un sistema de coordenadas Cartesiano x,y,z. Es importante comprender que el vector ![]() existe independientemente de cualquier sistema de base particular; el mismo vector puede ampliarse en muchos sistemas básicos diferentes. Los vectores de base
existe independientemente de cualquier sistema de base particular; el mismo vector puede ampliarse en muchos sistemas básicos diferentes. Los vectores de base ![]() , se denominan estos, vectores unitarios porque cada uno esta inscrito dentro de una esfera de radio 1, por ello su longitud es uno. ¿Y qué base es esta? Cualquiera que sea la unidad que esté utilizando para expresar la longitud del vector
, se denominan estos, vectores unitarios porque cada uno esta inscrito dentro de una esfera de radio 1, por ello su longitud es uno. ¿Y qué base es esta? Cualquiera que sea la unidad que esté utilizando para expresar la longitud del vector ![]() . Puede ayudarle a pensar en un vector de unidad como definir un paso a lo largo de un eje de coordinadas, por lo que una expresión como
. Puede ayudarle a pensar en un vector de unidad como definir un paso a lo largo de un eje de coordinadas, por lo que una expresión como
![]() (2.33)
(2.33)
Le expresa es tome cinco pasos en la dirección x positiva, dos pasos en la dirección y negativa y tres pasos en la dirección a positiva para llegar al punto (5,-2,3) desde el origen.
También puede recordar que la magnitud (módulo o norma) de un vector, es calculada generalmente por el concepto Euclidiano de distancia:
![]() (2.34)
(2.34)
Para el ejemplo (1.2)
![]()
La versión negativa de ![]() , es un vector de la misma longitud pero que apunta en la dirección opuesta, respetando una propiedad del espacio material, no haber longitudes negativas.
, es un vector de la misma longitud pero que apunta en la dirección opuesta, respetando una propiedad del espacio material, no haber longitudes negativas.
La adición de dos vectores, se puede hacer gráficamente, como lo muestra la figura siguiente:
 17.38.54.png)
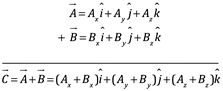 (2.35)
(2.35)
Otra operación importante es multiplicar un vector por un escalar, lo que cambia la longitud pero no la dirección del vector. Así que
![]()
El escalar, escala cada componente por igual (factor) significa que el vector ![]() , apunta en la misma dirección de
, apunta en la misma dirección de ![]() , pero su longitud o norma es
, pero su longitud o norma es
![]()
Por lo tanto, la longitud del vector se escala por el factor ![]() , pero su dirección sigue siendo la misma ( a menos que el valor de la longitud sea negativa, en cuyo caso la dirección se convierte, pero el vector sigue estando en la misma línea.
, pero su dirección sigue siendo la misma ( a menos que el valor de la longitud sea negativa, en cuyo caso la dirección se convierte, pero el vector sigue estando en la misma línea.
Esto es relevante en la mecánica cuántica. Las soluciones de las ecuaciones de Schrödinger son funciones de onda cuánticas que se comportan como vectores de mayor dimensión generalizada. Eso significa que se pueden agregar juntas para formar una nueva función de onda y se pueden multiplicar por escalera sin cambiar su “dirección”.
Además de sumar vectores, multiplicar vectores por escalera, y encontrar sus magnitudes es importante las operaciones de producto interno o producto punto, entre dos vectores, usualmente se denota
![]()
![]() (2.36)
(2.36)
En el que ![]() es el ángulo entre
es el ángulo entre ![]() . En coordinadas cartesianas, el producto interno puede encontrarse multiplicando las componentes correspondientes y sumando los resultados:
. En coordinadas cartesianas, el producto interno puede encontrarse multiplicando las componentes correspondientes y sumando los resultados:
![]() (2.37)
(2.37)
Si los vectores ![]() , note que si son perpendiculares
, note que si son perpendiculares ![]() , es decir
, es decir
![]() (2.38)
(2.38)
Alternativamente si están perpendiculares ![]() , es decir a 90º
, es decir a 90º
![]()
El vector punto el mismo da:
![]()
Una versión generalizada del producto interno o punto es extremadamente útil en la mecánica cuántica, por lo que vale la pena un poco de tiempo para pensar en lo que sucede cuando se realiza la operación como ![]() . En la figura
. En la figura
 18.12.46.png)
puede darse cuenta que el producto punto es la proyección del vector ![]() sobre
sobre ![]() , como puede apreciarse en la figura. Es producto interno es la longitud de la proyección a 90º sobre dirección del vector
, como puede apreciarse en la figura. Es producto interno es la longitud de la proyección a 90º sobre dirección del vector ![]() . Desde esta perspectiva, el producto punto indica cuánto del vector
. Desde esta perspectiva, el producto punto indica cuánto del vector ![]() se encuentra a lo largo de la dirección de
se encuentra a lo largo de la dirección de ![]() . De cualquier manera el producto punto proporciona una medida de cuánto un vector contribuye a la dirección de otro. Para que este concepto sea más específico, considere lo que obtiene dividiendo el producto punto por la magnitud de
. De cualquier manera el producto punto proporciona una medida de cuánto un vector contribuye a la dirección de otro. Para que este concepto sea más específico, considere lo que obtiene dividiendo el producto punto por la magnitud de ![]() veces la magnitud de
veces la magnitud de ![]() . Una medida de ángulo entre los vectores, ene rango de 0º a 90º. Así que si dos vectores son paralelos cada uno contribuye con su longitud a la dirección del otro, pero si son perpendiculares, ninguno hace ninguna contribución a la dirección del otro. Esta comprensión del producto punto hace que sea fácil componer los resultados de tomar el producto punto entre pares de vectores unitarios cartesianos:
. Una medida de ángulo entre los vectores, ene rango de 0º a 90º. Así que si dos vectores son paralelos cada uno contribuye con su longitud a la dirección del otro, pero si son perpendiculares, ninguno hace ninguna contribución a la dirección del otro. Esta comprensión del producto punto hace que sea fácil componer los resultados de tomar el producto punto entre pares de vectores unitarios cartesianos:
 19.12.59.png)
Los vectores de unidad cartesianos se llaman ortonormales porque son ortogonales cada uno es perpendicular a los demás, así que como normalizados de magnitud un. También se denominan un conjunto completo, porque cualquier vector en el espacio tridimensional puede estar formado por una combinación ponderada de estos tres vectores base.
 19.16.25.png)
En resumen. Esta técnica de excavación de los componentes de un vector utiliza dos vectores de producto punto y las bases son extremadamente valiosas en la mecánica cuántica. Los vectores son representaciones matemáticas de cantidades que pueden expandirse como una serie de componentes, cada uno de los cuales pertenece a un indicador direccional llamado vector base. Un vector base se puede agregar a otro vector para producir un nuevo vector, y un vector puede ser multiplicado por un escalar o por otro vector. Este producto punto o producto interno entre dos vectores, produce un resultado escalar proporcional a la proyección de uno de los vectores a lo largo de la dirección del otro. Los componentes de un vector en un sistema de base ortonormal, se pueden encontrar colocando cada vector base en el vector.
Justo como un vector se puede expresar como una combinación ponderada de vectores de base, una función de onda cuántica se puede expresar como una combinación ponderada de funciones de onda base. Una versión generalizada del producto punto llamado producto interno se puede utilizar para calcular cuánto contribuye cada función de onda al componente de la suma, y esto determina la probabilidad de varios resultados de medición.
2.5.1 Notación de Dirac
Para hacer la conexión entre vectores y funciones de onda cuántica es importante que se nos demos cuenta de que los componentes vectoriales como Ax,Ay,Az tienen significado solo cuando están vinculados a un conjunto de vectores base ![]() . Si hubiera elegido representar al vector base alineados con ejes girados, podría haber escrito el mismo vector A que
. Si hubiera elegido representar al vector base alineados con ejes girados, podría haber escrito el mismo vector A que
![]()
Donde las versiones primadas designan que los vectores base están girados respecto a los clásicos ![]() .
.
Expandir un vector ![]() en términos de vectores base diferentes, los componentes vectoriales del vector pueden cambiar, pero los nuevos componentes y nuevos vectores base se suman para dar el mismo vector. Incluso se puede optar por usar un conjunto de no cartesiano de vectores de base, tales como el esférico:
en términos de vectores base diferentes, los componentes vectoriales del vector pueden cambiar, pero los nuevos componentes y nuevos vectores base se suman para dar el mismo vector. Incluso se puede optar por usar un conjunto de no cartesiano de vectores de base, tales como el esférico:
![]()
Una vez más diferentes componentes vectoriales pueden cambiar, pero los nuevos componentes y nuevos vectores base se suman para dar el mismo vector. ¿Cual es la ventaja de usar un conjunto de vectores base u otro? Dependiendo de la geometría de la situación, puede ser más sencillo representar o manipular vectores en una base particular. Pero una vez que hay especificado una base, un vector puede representarse simplemente escribiendo sus componentes en esa base como un conjunto ordenado de números.
Por ejemplo, podría escribir sus componentes en una matriz de una sola columna
![]()
 12.22.29.png)
Este sistema base, en el que cada vector de base tiene solo un componente distinto de cero y el valor de ese componente es +1, se denomina base estándar o natural.
Si expresa un vector en base esférica:
 12.22.34.png)
En forma de columna
 12.22.39.png)
Cada vez que vea un vector representado como una columna de componentes, es esencial que entienda el sistema base al que pertenecen esos componentes. Siempre y cuando recuerde que los vectores pueden representarse en diferentes bases.
En la mecánica cuántica es probable que encuentres entidades llamadas Ket, escritas con una barra vertical a la izquierda y con corchetes en ángulo a la derecha e izquierda, un Ket ![]() , el Ket
, el Ket ![]() se puede expandir de la misma manera que el vector
se puede expandir de la misma manera que el vector![]() :
:
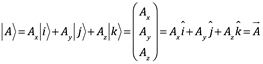
Así que si los kets son solo una forma diferente de representar vectores, ¿Por qué llamarlos Kets y escribiendo como vectores columna? Esta notación fue desarrollada pro el físico británico Paul Dirac en 1939, mientras trabajaba con una versión generalizada del producto punto llamado producto interno, escrito como ![]() . En este contexto, “generalizado” significa no restringido a vectores reales en el espacio físico tridimensional, por lo que el producto interno se puede utilizar con vectores abstractos de mayor dimensión con componentes complejos
. En este contexto, “generalizado” significa no restringido a vectores reales en el espacio físico tridimensional, por lo que el producto interno se puede utilizar con vectores abstractos de mayor dimensión con componentes complejos ![]() . Dirac se dio cuenta que el producto interno
. Dirac se dio cuenta que el producto interno ![]() podría dividirse conceptualmente en dos piezas, una mitad derecha que llamó un “bra” y una mitad derecha que él llamo Ket. En su conjunto lo llamo Braket
podría dividirse conceptualmente en dos piezas, una mitad derecha que llamó un “bra” y una mitad derecha que él llamo Ket. En su conjunto lo llamo Braket ![]() . En notación convencional
. En notación convencional ![]() y la de Dirac:
y la de Dirac:
![]()
Note que la barra que forma al Braket es la multiplicación ![]() . Para calcular el producto interno
. Para calcular el producto interno ![]() , comience representando el vector
, comience representando el vector ![]() como un ket:
como un ket:
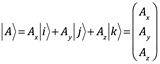
Los subíndices indican que estos componentes son cartesianos. Ahora la forma bra ![]() toma el conjugado complejo de cada componente y se escribe
toma el conjugado complejo de cada componente y se escribe
![]()
El producto interno ![]() es entonces
es entonces
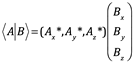
Según la multiplicación de matrices,
![]()
Como cabría esperar de una versión generalizada del producto punto. Así que los kets pueden ser representados por vectores columna y los bra por vectores fila, pero una pregunta común entre los estudiantes es en la mecánica cuántica ¿Qué son exactamente kets y los bra? La respuesta a la primera, es que los kets son objetos matemáticos que son miembros de un espacio vectorial o llamado también espacio lineal. En el apartado 1.3 de este curso se discute el tema de espacios vectoriales. Un espacio vectorial es solo una colección de vectores que se comportan de acuerdo a una cierta regla. Esas reglas incluyen la adición de vectores para producir nuevos vectores que son parte del mismo espacio, y la multiplicación de un vector por un escalar, produciendo una versión escalada del vector, que sigue en el mismo espacio. Puesto que trataremos con vectores generalizados en lugar de vectores en un espacio físico tridimensional, en lugar de etiquetar los componentes x,y,z los numeramos. Y en su lugar los vectores base 1,2,1…N. Así que la ecuación es
![]()
Se transforma en
![]()
En el que Ai representa el componente ket para la base del ket ![]() .
.
Pero al igual que el vector ![]() es el mismo vector, independientemente del sistema de coordinadas que utilice para expresar sus componentes, el Ket
es el mismo vector, independientemente del sistema de coordinadas que utilice para expresar sus componentes, el Ket ![]() existe independientemente de cualquier conjunto particular de bases kets, es decir los kets son independientes de la base. Así que
existe independientemente de cualquier conjunto particular de bases kets, es decir los kets son independientes de la base. Así que ![]() se comporta igual que el vector
se comporta igual que el vector ![]() .
.
Esto puede ayudar a pensar un ket como este:
![]()
La barra de este objeto se comporta como un vector. El “nombre” del vector al que corresponde este ket.
Una vez que haya elegido un sistema base, ¿por qué escribir los componentes de un ket como vector columna? Una razón es que permite aplicar las reglas de multiplicación de matrices para formar productos escalares. Los otros miembros de esos productos escalares son bras y la definición de un bra es algo diferente de la de un ket. Esto se debe a que un bra es una función línea, también llamado “covector” o forma única que se combina con un ket para producir un escalar; los matemáticos dicen que los bras mapean vectores al campo de los escalares. Entonces, ¿Qué es una función lineal? Es esencialmente un dispositivo matemático, como un instrucción que opera a otro objeto. Por lo tanto, un bra opera un key y el resultado de esa operación es un escalar. ¿Cómo se asigna esta operación a un escalar? Siguiendo las reglas del producto escalar, que ya hemos visto para dos vectores reales.
Los bra no habitan el mismo espacio vectorial que los kets: están en su propio espacio vectorial kets que se llama “espacio dual” al espacio kets. Dentro de ese espacio, los bras se pueden sumarse juntos y multiplicarse por los escalares para producir nuevos bras, al igual que kets en su espacio.
Una razón por la que el espacio de los bras se llama dual al espacio de los kets es que para cada ket existe un bras correspondiente y cuando un bras opera en su correspondiente doble ket, el resultado escalar es el acuerdo de la norma del ket:
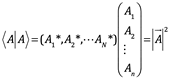
Así como el producto punto de un vector real consigo mismo da el cuadrado de la longitud del vector. Tenga en cuenta que el bra del vector es el dual del ket ![]() , que se escribe como
, que se escribe como ![]() , no
, no ![]() . Esto se debe a que el símbolo dentro de los corchetes de un ket o un bra es simplemente un nombre. Para un ket, ese nombre es el nombre del vector que representa el ket. Pero para un bra, el nombre dentro de los corchetes es el nombre del ket correspondiente al bra. Por lo tanto, el bra
. Esto se debe a que el símbolo dentro de los corchetes de un ket o un bra es simplemente un nombre. Para un ket, ese nombre es el nombre del vector que representa el ket. Pero para un bra, el nombre dentro de los corchetes es el nombre del ket correspondiente al bra. Por lo tanto, el bra ![]() corresponde al ket
corresponde al ket ![]() , pero los compones del bra
, pero los compones del bra ![]() son los conjugados de los componentes de
son los conjugados de los componentes de ![]() .
.
Tal vez quiera pensar en un bra como este:
![]()
Dice que se trata de un dispositivo para convertir un vector ket en un escalar.
El nombre del vector ket al que corresponde este bra.
En la notación Dirac, un vector se representa como una opción independiente de la base y sus componentes en una base especifica se representan mediante un vector columna. Cada ket tiene un bra correspondiente; su componente en una base especificada son los conjugados complejos de los componentes del ket correspondiente y están representados por un vector fila. El producto interno de dos vectores se forma multiplicando el bra correspondiente al primer vector por el ket correspondiente al segundo vector, haciendo un “bra-ket” o bracket.
Las soluciones a las ecuaciones de Schrödinger son funciones de espacio y tiempo, llamadas funciones de onda cuántica, que son las proyecciones de los estados cuánticos sobre un sistema base especificado. Los estados cuánticos pueden representarse útilmente como kets en la mecánica cuántica. Como kets, los estados cuánticos no están vinculados a ningún sistema base en particular, pero pueden ampliarse utilizando estados básicos de posición, impulso, energía u otra cantidad. La notación de Dirac también es útil para proporcionar una representación independiente de la base de los productos internos, los operadores hermitian, los operadores de proyección y los valores de expectativa.
2.6 Normas
Consideramos un conjunto de objetos S que tiene un operador de tipo suma, +, una identidad aditiva correspondiente, 0 y una multiplicación escalar; es decir, una multiplicación de los objetos por un número real (o complejo). En dicho conjunto, una norma es una función, · de S a que satisface las siguientes tres condiciones:
1. No negatividad y mapeo de la identidad aditiva:
si ![]() , entonces
, entonces ![]() y
y ![]() .
.
2. Relación de la multiplicación escalar con la multiplicación real:
hecha ![]() de verdad a.
de verdad a.
3. Desigualdad triangular:
![]()
(Si la propiedad 1 se relaja para requerir solo ![]() para
para ![]() , la función se llama seminorma). Debido a que una norma es una función cuyo argumento es un vector, a menudo también usamos una notación funcional como p(x) para representar una norma del vector x. Los conjuntos de varios tipos de objetos (funciones, por ejemplo) pueden tener normas, pero nuestro interés en el contexto actual está en las normas para vectores y (más adelante) para las matrices. De hecho, las tres propiedades anteriores definen una norma más general para otros tipos de objetos matemáticos para los que se definen en una suma, una identidad aditiva y la multiplicación por un escalar. Las normas se definen para las matrices, como veremos más adelante, son dos tipos diferentes de multiplicación usados ??en la propiedad 2 y dos tipos diferentes de suma usados ??en la propiedad 3.
, la función se llama seminorma). Debido a que una norma es una función cuyo argumento es un vector, a menudo también usamos una notación funcional como p(x) para representar una norma del vector x. Los conjuntos de varios tipos de objetos (funciones, por ejemplo) pueden tener normas, pero nuestro interés en el contexto actual está en las normas para vectores y (más adelante) para las matrices. De hecho, las tres propiedades anteriores definen una norma más general para otros tipos de objetos matemáticos para los que se definen en una suma, una identidad aditiva y la multiplicación por un escalar. Las normas se definen para las matrices, como veremos más adelante, son dos tipos diferentes de multiplicación usados ??en la propiedad 2 y dos tipos diferentes de suma usados ??en la propiedad 3.
Un espacio vectorial junto con una norma se llama espacio normado. Para algunos tipos de objetos, una norma de un objeto puede llamarse su "longitud" o su "tamaño". (Recuerde la ambigüedad de la "longitud" de un vector).
2.6.1 Vectores normalizados (vectores unitarios)
La norma euclidiana de un vector corresponde a la longitud del vector x de forma natural; es decir, está de acuerdo con nuestra intuición con respecto a la "longitud". Aunque, como hemos visto, esta es solo una de las muchas normas vectoriales, en la mayoría de las aplicaciones es la más útil. (Sin embargo, debo advertirle que ocasionalmente usaremos descuidada pero naturalmente "longitud" para referirme al orden de un vector; es decir, el número de elementos. Este uso es común en paquetes de software de computadora como R y SAS IML y el software necesariamente da forma a nuestro vocabulario). Dividir un vector dado por su longitud normaliza el vector, y se dice que el vector resultante con longitud 1 está normalizado; así
![]()
Es un vector normalizado. Los vectores normalizados a veces se denominan "vectores unitarios", aunque generalmente reservaremos este término para un tipo especial de vector normalizado. Un vector normalizado también se denomina a veces "vector normal". Uso "vector normalizado" para un vector como ![]() se usa “vector normal" para denotar un vector que es ortogonal a un subespacio.
se usa “vector normal" para denotar un vector que es ortogonal a un subespacio.
2.6.2 "Inverso" de un vector
Debido a que el mapeo de un producto interno lleva los elementos de un espacio a un espacio diferente (el producto interno de los vectores lleva elementos de ![]() a
a ![]() ), el concepto de un inverso para el producto interno no tiene sentido de la manera habitual. En primer lugar, no hay identidad con respecto al producto interno.
), el concepto de un inverso para el producto interno no tiene sentido de la manera habitual. En primer lugar, no hay identidad con respecto al producto interno.
Sin embargo, a menudo en aplicaciones, los productos internos se combinan con la multiplicación de vector escalar habitual en la forma ![]() ; por lo tanto, para x dado, puede ser de interés determinar y tal que
; por lo tanto, para x dado, puede ser de interés determinar y tal que ![]() , la identidad multiplicativa en
, la identidad multiplicativa en ![]() . Para x en
. Para x en ![]() tal que
tal que ![]() , la identidad aditiva en
, la identidad aditiva en ![]() ,
,
![]()
satisface de forma única ![]() . Se llama el inverso de Samelson del vector x y a veces se denota como
. Se llama el inverso de Samelson del vector x y a veces se denota como ![]() o como
o como ![]() . A veces también se le llama inverso del vector de Moore-Penrose porque satisface las cuatro propiedades de la definición inverso de Moore-Penrose.
. A veces también se le llama inverso del vector de Moore-Penrose porque satisface las cuatro propiedades de la definición inverso de Moore-Penrose.
La norma en la ecuación anterior, es obviamente la norma euclidiana (debido a la forma en que definimos ![]() ), pero la idea de la inversa también podría extenderse a otras normas asociadas con otros productos internos.
), pero la idea de la inversa también podría extenderse a otras normas asociadas con otros productos internos.
El inverso de Samelson tiene una buena interpretación geométrica: es el punto inverso de x con respecto a la esfera unitaria en ![]() . Este inverso surge en el algoritmo vectorial utilizado para acelerar la convergencia de secuencias vectoriales en cálculos numéricos de Wynn 1962[1].
. Este inverso surge en el algoritmo vectorial utilizado para acelerar la convergencia de secuencias vectoriales en cálculos numéricos de Wynn 1962[1].
2.6.3 Métricas y distancias
A menudo es útil considerar qué tan separados están dos objetos; es decir, la "distancia" entre ellos. Una medida de distancia razonable debería satisfacer ciertos requisitos, como ser un número real no negativo. Una función Δ que mapea cualquiera de los dos objetos en un conjunto S a ![]() se llama una métrica en S si, para todos los x, y, y z en S, cumple las siguientes tres condiciones:
se llama una métrica en S si, para todos los x, y, y z en S, cumple las siguientes tres condiciones:
![]()
![]()
![]()
Estas condiciones corresponden de manera intuitiva a las propiedades que esperamos de una distancia entre objetos. Un espacio vectorial junto con una métrica definida en él se denomina espacio métrico. Un espacio vectorial normado es un espacio métrico porque la norma puede inducir una métrica. A continuación, podemos hablar casi indistintamente de un espacio producto interno, un espacio normado o un espacio métrico, pero debemos reconocer que ninguno es un caso especial del otro. (Por ejemplo, recuerde que un espacio normado cuya norma es la norma L1 no es equivalente a un espacio producto interno).
2.6.4 Métricas inducidas por normas
Si substracción y una norma se definen para los elementos de S, la forma más común de formar una métrica es mediante el uso de la norma. Si ![]() es una norma, podemos verificar que
es una norma, podemos verificar que
![]()
es una métrica mediante el uso de las propiedades de una norma para establecer las tres propiedades de una métrica anterior. La norma en la ecuación anterior puede, por supuesto, ser inducida por un producto interno. Los productos internos generales, las normas y las métricas definidas anteriormente son relevantes en una amplia gama de aplicaciones. Los conjuntos en los que se definen pueden consistir en varios tipos de objetos. En el contexto de los vectores reales, el producto interno más común es el producto punto; la norma más común es la norma euclidiana que surge del producto escalar; y la métrica más común es la definida por la norma euclidiana, llamada distancia euclidiana.
2.6.5 Convergencia de secuencias de vectores
Una secuencia de números reales a1, a2,. . . se dice que converge a un número finito a si para cualquier dado ![]() hay un entero M tal que, para k > M,
hay un entero M tal que, para k > M, ![]() , y escribimos
, y escribimos ![]() , o podemos escribir ak → a como k → ∞.
, o podemos escribir ak → a como k → ∞.
Definimos la convergencia de una secuencia de vectores en un espacio vectorial normado en términos de la convergencia de una secuencia de sus normas, que es una secuencia de numeros reales. Decimos que una secuencia de vectores x1, x2,. . . (del mismo orden) converge al vector x con respecto a la norma ![]() si la secuencia de números reales
si la secuencia de números reales ![]() converge a 0. Debido a los límites (2.39), la elección de la norma es irrelevante (para espacios vectoriales de dimensiones finitas), por lo que la convergencia de una secuencia de vectores está bien definida sin referencia a una norma específica. (Esta es una razón por la cual la equivalencia de las normas es una propiedad importante).
converge a 0. Debido a los límites (2.39), la elección de la norma es irrelevante (para espacios vectoriales de dimensiones finitas), por lo que la convergencia de una secuencia de vectores está bien definida sin referencia a una norma específica. (Esta es una razón por la cual la equivalencia de las normas es una propiedad importante).
Una secuencia de vectores x1, x2,. . . en el espacio métrico V que se acerca arbitrariamente el uno al otro (medido por la métrica dada) se llama secuencia de Cauchy. (En una secuencia de Cauchy x1, x2,..., Para cualquier ![]() hay un número N tal que para i, j> N, Δ (xi, xj) <
hay un número N tal que para i, j> N, Δ (xi, xj) <![]() ). Intuitivamente, dicha secuencia debería converger a algún vector fijo en V, pero este no es necesariamente el caso. Se dice que un espacio métrico en el que cada secuencia de Cauchy converge a un elemento en el espacio es un espacio métrico completo o simplemente un espacio completo. El espacio
). Intuitivamente, dicha secuencia debería converger a algún vector fijo en V, pero este no es necesariamente el caso. Se dice que un espacio métrico en el que cada secuencia de Cauchy converge a un elemento en el espacio es un espacio métrico completo o simplemente un espacio completo. El espacio ![]() (con cualquier norma) está completo.
(con cualquier norma) está completo.
Un espacio normado completo se llama espacio de Banach, y un espacio de producto interno completo se llama espacio de Hilbert. Está claro que un espacio de Hilbert es un espacio de Banach (porque su producto interno induce una norma). Como hemos indicado, un espacio con una norma inducida por un producto interno, como un espacio de Hilbert, tiene una estructura interesante. La mayoría de los espacios vectoriales encontrados en las aplicaciones estadísticas son espacios de Hilbert. El espacio ![]() con la norma L2 es un espacio de Hilbert.
con la norma L2 es un espacio de Hilbert.
2.7 Vectores ortogonales y espacios de vectores ortogonales
Dos vectores v1 y v2 de modo que
![]()
se dice que son ortogonales, y esta condición se denota por v1 ⊥ v2. (A veces excluimos el vector cero de esta definición, pero no es importante hacerlo). Los vectores normalizados que son todos ortogonales entre sí, se denominan vectores ortonormales.
Un conjunto de vectores distintos de cero que son mutuamente ortogonales son necesariamente linealmente independientes. Para ver esto, lo mostramos para dos vectores ortogonales y luego indicamos el patrón que se extiende a tres o más vectores. Primero, supongamos que v1 y v2son distintos de cero y son ortogonales; es decir, ![]() . Vemos de inmediato que si hay un escalar a tal que v1 = av2, a debe ser distinto de cero y tenemos una contradicción porque
. Vemos de inmediato que si hay un escalar a tal que v1 = av2, a debe ser distinto de cero y tenemos una contradicción porque ![]() . Por lo tanto, concluimos que v1 y v2 son independientes (no hay tal que v1 = av2). Para tres vectores mutuamente ortogonales, v1, v2 y v3, consideramos v1 = av2 + bv3 para a o b distinto de cero, y llegamos a la misma contradicción.
. Por lo tanto, concluimos que v1 y v2 son independientes (no hay tal que v1 = av2). Para tres vectores mutuamente ortogonales, v1, v2 y v3, consideramos v1 = av2 + bv3 para a o b distinto de cero, y llegamos a la misma contradicción.
Se dice que dos espacios vectoriales V1 y V2 son ortogonales, escritos V1⊥ V2, si cada vector en uno es ortogonal a cada vector en el otro. Si V1⊥ V2 y V1⊕ V2 = ![]() , entonces V2 se llama complemento ortogonal de V1, y esto se escribe como
, entonces V2 se llama complemento ortogonal de V1, y esto se escribe como ![]() . En términos más generales, si V1⊥ V2 y V1⊕ V2 = V, entonces V2 se llama el complemento ortogonal de V1 con respecto a V. Esta es obviamente una relación simétrica; si V2 es el complemento ortogonal de V1, entonces V1 es el complemento ortogonal de V2.
. En términos más generales, si V1⊥ V2 y V1⊕ V2 = V, entonces V2 se llama el complemento ortogonal de V1 con respecto a V. Esta es obviamente una relación simétrica; si V2 es el complemento ortogonal de V1, entonces V1 es el complemento ortogonal de V2.
Se dice que un vector que es ortogonal a todos los vectores en un espacio vectorial dado, es ortogonal a ese espacio o normal a ese espacio. Tal vector se llama un vector normal a ese espacio.
Si B1 es un conjunto de bases para V1, B2 es un conjunto de bases para V2, y V2 es el complemento ortogonal de V1 con respecto a V, entonces B1∪ B2 es un conjunto de bases para V. Es un conjunto de bases porque desde V1 y V2 son ortogonales, debe ser el caso de que B1∩ B2 = ∅.
Si V1⊂ V, V2⊂ V, V1⊥ V2 y dim (V1) + dim (V2) = dim (V), entonces
![]()
es decir, V2 es el complemento ortogonal de V1. Vemos esto dejando primero que B1 y B2 sean bases para V1 y V2. Ahora V1⊥ V2 implica que B1∩ B2 = ∅ y dim (V1) + dim (V2) = dim (V) implica # (B1) + # (B2) = # (B), para cualquier conjunto de bases B para V; por lo tanto, B1∪ B2 es una base establecida para V.
La intersección de dos espacios vectoriales ortogonales consiste solo en el vector cero.
Un conjunto de vectores linealmente independientes se puede asignar a un conjunto de vectores mutuamente ortogonales (y ortonormales) mediante las transformaciones de Gram-Schmidt.
2.8 El "vector uno”
El vector con todos los elementos iguales a 1 que mencionamos anteriormente es útil en varias operaciones de vectores. Llamamos a esto el "vector uno” y lo denotamos por 1 o por 1n. El único vector puede usarse en la representación de la suma de los elementos en un vector:
![]()
El vector uno también se llama el "vector sumador".
2.9 Propiedades de los vectores coordenadas cartesianas y geométricas
Los puntos en una geometría cartesiana pueden identificarse con vectores, y esta definición geométrica puede motivar varias definiciones y propiedades de los vectores. En esta interpretación, los vectores son segmentos de línea dirigida con un origen común. Las propiedades geométricas se pueden ver más fácilmente en términos de un sistema de coordenadas cartesianas, pero las propiedades de los vectores definidos en términos de una geometría cartesiana tienen análogos en la geometría euclidiana sin un sistema de coordenadas. En dicho sistema, solo se definen la longitud y la dirección, y dos vectores se consideran el mismo vector si tienen la misma longitud y dirección. En general, no asumiremos que hay una "ubicación" o "posición" asociada con un vector.
2.9.1 Geometría cartesiana
Un sistema de coordenadas cartesianas en d dimensiones se define por d vectores unitarios, ei en la ecuación ![]() , cada uno con d elementos. Un vector unitario también se denomina eje principal del sistema de coordenadas. El conjunto de vectores unitarios es ortonormal. (Hay un número implícito de elementos de un vector unitario que se infiere del contexto. También entre paréntesis, observamos que la frase "vector unitario" a veces se usa para referirse a un vector cuya suma de elementos al cuadrado es 1, es decir , cuya longitud, en el sentido de distancia euclidiana, es 1. Como mencionamos anteriormente, nos referimos a este último tipo de vector como un "vector normalizado".) La suma de todos los vectores unitarios es el vector uno:
, cada uno con d elementos. Un vector unitario también se denomina eje principal del sistema de coordenadas. El conjunto de vectores unitarios es ortonormal. (Hay un número implícito de elementos de un vector unitario que se infiere del contexto. También entre paréntesis, observamos que la frase "vector unitario" a veces se usa para referirse a un vector cuya suma de elementos al cuadrado es 1, es decir , cuya longitud, en el sentido de distancia euclidiana, es 1. Como mencionamos anteriormente, nos referimos a este último tipo de vector como un "vector normalizado".) La suma de todos los vectores unitarios es el vector uno:
![]()
Un punto x con coordenadas cartesianas (x1,..., xd) está asociado con un vector desde el origen hasta el punto, es decir, el vector (x1,..., xd). El vector se puede escribir como la combinación lineal.
![]()
o, equivalentemente, como
![]()
(Esta es una expansión de Fourier).
2.9.2 Proyecciones
La proyección del vector y sobre el vector no nulo x es el vector
Esta definición es consistente con una interpretación geométrica de vectores como segmentos de línea dirigida con un origen común. La proyección de y sobre x es el producto interno de la x e y normalizada multiplicada por la x normalizada; es decir, ![]() , donde
, donde ![]() . Observe que el orden de y y x es el mismo. Una propiedad importante de una proyección es que cuando se resta del vector proyectado, el vector resultante, llamado "residual", es ortogonal a la proyección; es decir, si...
. Observe que el orden de y y x es el mismo. Una propiedad importante de una proyección es que cuando se resta del vector proyectado, el vector resultante, llamado "residual", es ortogonal a la proyección; es decir, si...
 13.30.21.png)
Proyecciones y ángulos
entonces r y ![]() son ortogonales, como podemos ver fácilmente al tomar su producto interno. Observe también que la relación pitagórica tiene:
son ortogonales, como podemos ver fácilmente al tomar su producto interno. Observe también que la relación pitagórica tiene:
2.9.3 Ángulos entre vectores
El ángulo entre los vectores no nulos x e y está determinado por su coseno, que podemos calcular a partir de la longitud de la proyección de un vector sobre el otro. Por lo tanto, denotando el ángulo entre los vectores no nulos x e y como ángulo
![]() (x,y), definimos
(x,y), definimos
![]()
La palabra "ortogonal" se define apropiadamente por la ecuación ![]() porque la ortogonalidad en ese sentido es equivalente a la propiedad geométrica correspondiente. (El coseno es 0.)
porque la ortogonalidad en ese sentido es equivalente a la propiedad geométrica correspondiente. (El coseno es 0.)
2.9.4 Conjuntos de bases ortonormales
A menudo se elige una base para un espacio vectorial para que sea un conjunto ortonormal porque es fácil trabajar con los vectores en dicho conjunto. Si ![]() es una base ortonormal establecida para un espacio, entonces un vector x en ese espacio puede expresarse como
es una base ortonormal establecida para un espacio, entonces un vector x en ese espacio puede expresarse como
![]()
y debido a la ortonormalidad, tenemos
![]()
(Vemos esto tomando el producto interno de ambos lados con vi.) Una representación de un vector como una combinación lineal de vectores de base ortonormales, como en la ecuación ![]() , se llama expansión de Fourier, y los ci se llaman coeficientes de Fourier .
, se llama expansión de Fourier, y los ci se llaman coeficientes de Fourier .
Al tomar el producto interno de cada lado de la ecuación ![]() consigo mismo, tenemos la identidad de Parseval:
consigo mismo, tenemos la identidad de Parseval:
![]()
Esto muestra que la norma L2 es la misma que la norma en la ecuación
![]() para el caso de una base ortogonal.
para el caso de una base ortogonal.
Aunque la expansión de Fourier no es única porque podría elegirse un conjunto de bases ortogonales diferentes, la identidad de Parseval elimina parte de la arbitrariedad en la elección; no importa qué base se use, la suma de los cuadrados de los coeficientes de Fourier es igual al cuadrado de la norma que surge del producto interno. ("El" producto interno significa el producto interno utilizado para definir la ortogonalidad).
Otra expresión útil de la identidad de Parseval en la expansión de Fourier
![]()
(porque el término en el lado izquierdo es 0). La expansión ![]() es un caso especial de una expansión muy útil en un conjunto de bases ortogonales. En los espacios vectoriales de dimensión finita que consideramos aquí, la serie es finita. En los espacios de funciones, la serie es generalmente infinita, por lo que los problemas de convergencia son importantes. Para diferentes tipos de funciones, pueden ser apropiados diferentes conjuntos de bases ortogonales. A menudo se usan polinomios, y hay algunos conjuntos estándar de polinomios ortogonales, como Jacobi, Hermite, etc. Especialmente para funciones periódicas, son útiles las funciones trigonométricas ortogonales.
es un caso especial de una expansión muy útil en un conjunto de bases ortogonales. En los espacios vectoriales de dimensión finita que consideramos aquí, la serie es finita. En los espacios de funciones, la serie es generalmente infinita, por lo que los problemas de convergencia son importantes. Para diferentes tipos de funciones, pueden ser apropiados diferentes conjuntos de bases ortogonales. A menudo se usan polinomios, y hay algunos conjuntos estándar de polinomios ortogonales, como Jacobi, Hermite, etc. Especialmente para funciones periódicas, son útiles las funciones trigonométricas ortogonales.
2.9.5 Productos cruzados en ![]()
El espacio vectorial ![]() es especialmente interesante porque sirve como un modelo útil del mundo real, y muchos procesos físicos pueden representarse como vectores en él.
es especialmente interesante porque sirve como un modelo útil del mundo real, y muchos procesos físicos pueden representarse como vectores en él.
Para el caso especial del espacio vectorial ![]() , otro producto vectorial útil es el producto cruz, que es un mapeo de
, otro producto vectorial útil es el producto cruz, que es un mapeo de ![]() ×
× ![]() a
a ![]() . Antes de continuar, observamos una sobrecarga del término "producto cruz" y del símbolo "×" utilizado para denotarlo. Si A y B son conjuntos, el producto cruz del conjunto o el producto cartesiano del conjunto de A y B es el conjunto que consta de todos los dobles tonos (a, b) donde a se extiende sobre todos los elementos de A, y b se extiende independientemente sobre todos los elementos de B Por lo tanto,
. Antes de continuar, observamos una sobrecarga del término "producto cruz" y del símbolo "×" utilizado para denotarlo. Si A y B son conjuntos, el producto cruz del conjunto o el producto cartesiano del conjunto de A y B es el conjunto que consta de todos los dobles tonos (a, b) donde a se extiende sobre todos los elementos de A, y b se extiende independientemente sobre todos los elementos de B Por lo tanto, ![]() ×
× ![]() es el conjunto de todos los pares de todos los 3-vectores reales. El producto vectorial cruzado de los 3-vectores
es el conjunto de todos los pares de todos los 3-vectores reales. El producto vectorial cruzado de los 3-vectores
![]()
y
![]()
escrito x × y, se define como
![]()
El producto cruz tiene las siguientes propiedades, que son inmediatamente obvias de la definición:
1. Auto- nilpotencía:
x × x = 0, para todas las x.
2. Anticonmutatividad:
x × y = −y × x
3. Factorización de la multiplicación escalar;
ax × y = a (x × y) para real a.
4. Relación de la adición de vectores a la adición de productos cruzados:
(x + y) × z = (x × z) + (y × z)
El producto cruzado tiene la propiedad importante (a veces tomada como la definición):
![]()
donde e es un vector tal que ![]() y
y ![]() , y el ángulo(y, x) se interpreta como el “ángulo más pequeño a través del cual y se rotaría para convertirse en un múltiplo no negativo de x ". En la definición de ángulos entre vectores dada,
, y el ángulo(y, x) se interpreta como el “ángulo más pequeño a través del cual y se rotaría para convertirse en un múltiplo no negativo de x ". En la definición de ángulos entre vectores dada, ![]() . Como señalamos allí, a veces es importante distinguir la dirección del ángulo, y este es el caso en la ecuación
. Como señalamos allí, a veces es importante distinguir la dirección del ángulo, y este es el caso en la ecuación![]() , como en muchas aplicaciones en
, como en muchas aplicaciones en ![]() . La dirección de los ángulos en
. La dirección de los ángulos en ![]() a menudo se usa para determinar la orientación de los ejes principales en un sistema de coordenadas. El sistema de coordenadas a menudo se define como "diestro".
a menudo se usa para determinar la orientación de los ejes principales en un sistema de coordenadas. El sistema de coordenadas a menudo se define como "diestro".
El producto cruz es útil para modelar fenómenos en la naturaleza, que naturalmente se representan a menudo como vectores en ![]() . El producto cruzado también es útil en gráficos de computadora "tridimensionales" para determinar si una superficie dada es visible desde una perspectiva dada y para simular el efecto de la iluminación en una superficie.
. El producto cruzado también es útil en gráficos de computadora "tridimensionales" para determinar si una superficie dada es visible desde una perspectiva dada y para simular el efecto de la iluminación en una superficie.
Referencias
[1] Wynn, P. 1962. Acceleration techniques for iterated vector and matrix problems.
Mathematics of Computation 16:301–322.
_____________________________________________
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Lizbeth Guadalupe Villalon Magallan
Mónica Rico Reyes
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán