Texto universitario

_____________________________
Módulo 4: Matrices de transformación y factorización
En la mayoría de las aplicaciones del álgebra lineal, los problemas se resuelven mediante transformaciones de matrices. Una matriz dada (que representa alguna transformación de un vector) se transforma en sí misma. El ejemplo más simple de esto es resolver el sistema lineal Ax = b, donde la matriz A representa una transformación del vector x en el vector b. La matriz A se transforma a través de una sucesión de operaciones lineales hasta que x se determina fácilmente por el transformado A y el transformado b. Cada operación en la transformación de A es una multiplicación previa o posterior por alguna otra matriz. Cada matriz formada como producto debe ser equivalente a A; por lo tanto, para asegurar esto en general, cada matriz de transformación debe ser de rango completo. En los problemas propios, también realizamos una secuencia de pre o posmultiplicaciones. En este caso, cada matriz formada como producto debe ser similar a A; por tanto, cada matriz de transformación debe ser ortogonal. Desarrollamos transformaciones de matrices mediante transformaciones en las filas o columnas individuales.
4.1 Factorizaciones
Dada una matriz A, a menudo es útil descomponer A en el producto de otras matrices; es decir, para formar una factorización A = BC, donde B y C son matrices.
Nos referimos a esto como “factorización matricial”, o a veces como “descomposición matricial”, aunque este último término incluye representaciones más generales de la matriz, como la descomposición espectral.
La mayoría de los métodos de autoanálisis y de resolución de sistemas lineales proceden de la factorización de la matriz.
La factorización incluye:
• la factorización de rango completo de una matriz general,
• la factorización canónica equivalente de una matriz general.
• la factorización canónica similar o "factorización diagonal"
de una matriz diagonalizable (que es necesariamente cuadrada),
• la factorización canónica ortogonalmente similar de un
matriz simétrica (que es necesariamente diagonalizable),
• la raíz cuadrada de una matriz definida no negativa (que
es necesariamente simétrica), y
• la factorización de valor singular de una matriz general.
• la factorización LU ( LR y LDU) de una matriz general,
• la factorización QR de una matriz general, y
• la factorización de Cholesky de una matriz definida no negativa.
Estas factorizaciones son útiles tanto en la teoría como en la práctica.
Una factorización de una matriz A dada generalmente se efectúa mediante una serie de pre o posmultiplicaciones mediante matrices de transformación con propiedades simples y deseables. Una de estas matrices de transformación es la matriz de Gauss, Gij de la ecuación ![]() .
.
Otra clase importante de matrices de transformación son las matrices ortogonales. Las matrices de transformación ortogonal tienen algunas propiedades deseables.
4.2 Transformaciones geométricas lineales
En muchas aplicaciones importantes del álgebra lineal, un vector representa un punto en el espacio, y cada elemento del vector corresponde a un elemento de un sistema de coordenadas, generalmente un sistema cartesiano. Un conjunto de vectores describe un objeto geométrico, como un poliedro o un cono de Lorentz. Las operaciones algebraicas se pueden considerar como transformaciones geométricas que rotan, deforman o trasladan el objeto. Si bien estas transformaciones se utilizan a menudo en las dos o tres dimensiones que corresponden al espacio físico fácilmente percibido, tienen aplicaciones similares en dimensiones superiores. Pensar en las operaciones en álgebra lineal en términos de las operaciones geométricas asociadas a menudo proporciona una intuición útil.
Una transformación lineal de un vector x se efectúa multiplicando por una matriz A. Cualquier matriz A de n×m es una función o transformación de V1 a V2, donde V1 es un espacio vectorial de orden m y V2 es un espacio vectorial de orden n.
4.2.1 Propiedades de invariancia de transformaciones lineales
Una característica importante de una transformación es lo que deja sin cambios; es decir, sus propiedades de invariancia. Todas las transformaciones que discutiremos son transformaciones lineales porque conservan líneas rectas. Un conjunto de puntos que constituyen una línea recta se transforma en un conjunto de puntos que constituyen una línea recta.
Como se menciona en los cursos de geometría, las reflexiones y las rotaciones son transformaciones ortogonales y hemos visto que una transformación ortogonal conserva las longitudes de los vectores. También veremos que una transformación ortogonal conserva ángulos entre vectores. Una transformación que conserva longitudes y ángulos se llama transformación isométrica. Tal transformación también preserva áreas y volúmenes.
Otra transformación isométrica es una traslación, que es esencialmente la adición de otro vector.
Tabla 4.1 Propiedades de invarianza de transformación
___________________________________________________________________________
Transformación Preserva
Lineal líneas
Proyectiva líneas
Afines líneas, colinealidad
Corte líneas, colinealidad
Escalar líneas, ángulos (y, por tanto, colinealidad)
Rotación, líneas, ángulos, longitudes
Reflexión líneas, ángulos, longitudes
Traslación líneas, ángulos, longitudes
___________________________________________________________________________
Una transformación que conserva los ángulos se llama transformación isotrópica.
Un ejemplo de una transformación isotrópica que no es isométrica es una transformación de dilatación o escala uniforme, ![]() , donde a es un escalar. La transformación
, donde a es un escalar. La transformación ![]() , donde A es una matriz diagonal con no todos los elementos iguales, no preserva los ángulos; es una incrustación anisotrópica. Otra transformación anisotrópica es una transformación de corte,
, donde A es una matriz diagonal con no todos los elementos iguales, no preserva los ángulos; es una incrustación anisotrópica. Otra transformación anisotrópica es una transformación de corte, ![]() , donde A es lo mismo que una matriz de identidad, excepto por una sola fila o columna que tiene un uno en la diagonal pero elementos distintos de cero, posiblemente constantes, en las otras posiciones; por ejemplo,
, donde A es lo mismo que una matriz de identidad, excepto por una sola fila o columna que tiene un uno en la diagonal pero elementos distintos de cero, posiblemente constantes, en las otras posiciones; por ejemplo,
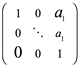
Aunque no conservan los ángulos, tanto el escalado anisotrópico como las transformaciones de corte conservan las líneas paralelas. Una transformación que conserva las líneas paralelas se denomina transformación afín. La conservación de líneas paralelas equivale a la conservación de la colinealidad, por lo que una caracterización alternativa de una transformación afín es aquella que conserva la colinealidad. De manera más general, podemos combinar transformaciones de escalado y corte no triviales para ver que la transformación Ax para cualquier matriz A no singular es afín. Es fácil ver que la adición de un vector constante a todos los vectores en un conjunto preserva la colinealidad dentro del conjunto, por lo que una transformación afín más general es ![]() para una matriz A no singular y un vector t.
para una matriz A no singular y un vector t.
Una transformación proyectiva, que utiliza el sistema de coordenadas homogéneo del plano proyectivo, conserva las líneas rectas, pero no las paralelas. Las transformaciones proyectivas son muy útiles en gráficos por computadora. En esas aplicaciones, no siempre queremos que las líneas paralelas se proyecten en el plano de visualización como líneas paralelas.
4.3 Transformaciones por matrices ortogonales
Ya hemos definido matrices ortogonales y consideramos algunas propiedades básicas. Las matrices ortogonales no son necesariamente cuadradas; pueden tener más filas que columnas o pueden tener menos. A continuación, consideraremos sólo matrices ortogonales con al menos tantas filas como columnas; es decir, si Q es una matriz de transformación ortogonal, entonces QTQ = I. Esto significa que una matriz ortogonal es de rango completo. Por supuesto, muchas matrices ortogonales útiles son cuadradas (y, obviamente, no singulares). Hay muchos tipos de matrices de transformación ortogonales. Como se señaló anteriormente, las matrices de permutación son matrices ortogonales cuadradas, y las hemos utilizado ampliamente para reorganizar las columnas y/o filas de matrices.
Como dijimos, las transformaciones por matrices ortogonales conservan las longitudes de los vectores. Las transformaciones ortogonales también conservan ángulos entre vectores, como podemos ver fácilmente. Si Q es una matriz ortogonal, entonces, para los vectores x e y, tenemos
![]()
y por lo tanto,
![]()
Por tanto, las transformaciones ortogonales conservan los ángulos. Hemos visto que si Q es una matriz ortogonal y
![]()
entonces A y B tienen los mismos valores propios (y se dice que A y B son ortogonalmente similares). Al formar la transposición, vemos inmediatamente que la transformación ![]() conserva la simetría; es decir, si A es simétrico, entonces B es simétrico.
conserva la simetría; es decir, si A es simétrico, entonces B es simétrico.
De la ecuación
![]()
Algunas normas matriciales se definen en términos de normas vectoriales. Para mayor claridad, denotaremos una norma vectorial como ![]() y una norma matricial como
y una norma matricial como ![]() . (Esta notación debe ser genérica; es decir,
. (Esta notación debe ser genérica; es decir, representa cualquier norma vectorial). Para la matriz
![]() , la norma matricial
, la norma matricial ![]() inducida por
inducida por ![]() se define por
se define por
![]()
Normas L1, L2 y L∞ de matrices simétricas. Para una matriz simétrica A, tenemos las relaciones obvias
![]()
La norma de la matriz L2 está relacionada con el radio espectral
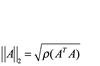
![]()
Por esta razón, una matriz ortogonal a veces se denomina matriz isométrica. Mediante la elección adecuada de x, es fácil ver en la ecuación
![]()
Esto tiene implicaciones importantes para la precisión de los cálculos numéricos. (El uso de cálculos con matrices ortogonales no hará que los problemas estén más "mal condicionados”). A menudo usamos transformaciones ortogonales que conservan longitudes y ángulos mientras rotamos ![]() o reflejan regiones de
o reflejan regiones de ![]() . Las transformaciones se denominan apropiadamente rotadores y reflectores, respectivamente.
. Las transformaciones se denominan apropiadamente rotadores y reflectores, respectivamente.
4.3.3 Rotaciones
La rotación más simple de un vector se puede considerar como la rotación de un plano definido por dos coordenadas alrededor de los otros ejes principales. Tal rotación cambia dos elementos de todos los vectores en ese plano y deja todos los demás elementos, que representan las otras coordenadas, sin cambios. Esta rotación se puede describir en un espacio bidimensional definido por el cambio de coordenadas, sin referencia a las otras coordenadas.
Considere la rotación del vector x a través del ángulo θ hacia el vector ![]() . La longitud se conserva, por lo que tenemos
. La longitud se conserva, por lo que tenemos ![]() . Con referencia a la figura siguiente, podemos escribir
. Con referencia a la figura siguiente, podemos escribir
 17.56.01.png)
Figura 4.1 Rotación de x
 17.57.30.png)
Ahora, desde la trigonometría elemental, sabemos
 17.57.55.png)
Como ![]() y
y ![]() , podemos combinar estas ecuaciones para obtener
, podemos combinar estas ecuaciones para obtener
 17.59.03.png)
Por lo tanto, multiplicar x por la matriz ortogonal
 17.59.28.png)
realiza la rotación de x.
Esta idea se extiende fácilmente a la rotación de un plano formado por dos coordenadas alrededor de todos los demás ejes principales (ortogonales). Por convención, asumimos rotaciones en el sentido de las agujas del reloj para ejes que aumentan en la dirección desde la que se ve el sistema. Por ejemplo, si hubiera un eje x3 en la figura anterior, apuntaría hacia el espectador. (Esto se llama sistema de coordenadas de la "mano derecha", porque si los dedos de la mano derecha del espectador apuntan en la dirección de la rotación, el pulgar apunta hacia el espectador).
La matriz de rotación sobre los ejes principales es la misma que una matriz de identidad con dos elementos diagonales cambiados a cos θ y los elementos fuera de la diagonal correspondientes cambiados a sen θ y −sin θ.
Para rotar un 3-vector, x, sobre el eje x2 en un sistema de coordenadas de la derecha, usaríamos la matriz de rotación
Una rotación de cualquier hiperplano en el espacio n puede formarse mediante n rotaciones sucesivas de hiperplanos formados por dos ejes principales. (En el espacio tridimensional, este hecho se conoce como teorema de rotación de Euler. Podemos ver que este es el caso, en el espacio tridimensional o, en general, por construcción).
Una rotación de un plano arbitrario se puede definir en términos de los cosenos de dirección de un vector en el plano antes y después de la rotación. En una geometría de coordenadas, la rotación de un plano se puede ver de manera equivalente como una rotación del sistema de coordenadas en la dirección opuesta. Esto se logra rotando los vectores unitarios ei en ![]() .
.
Un tipo especial de transformación que hace girar un vector para que sea perpendicular a un eje principal se llama rotación Givens. Otra rotación especial es la "reflexión" de un vector sobre otro vector. A continuación, hablamos de este tipo de rotación.
4.3.4 Reflexiones
Sean u y v vectores ortonormales, y sea x un vector en el espacio generado por u y v, entonces
x = c1u + c2v
para algunos escalares c1 y c2. El vector
![]()
es un reflejo de x a través de la línea definida por el vector v, o u⊥. Esta reflexión es una rotación en el plano definido por u y v a través de un ángulo del doble del tamaño del ángulo entre x y v.
La forma de ![]() , por supuesto, depende del vector v y su relación con x.
, por supuesto, depende del vector v y su relación con x.
En una aplicación común de reflexiones en cálculos algebraicos lineales, deseamos rotar un vector dado en un vector colineal con un eje de coordenadas; es decir, buscamos una reflexión que transforme un vector
x = (x1, x2,..., xn)
en un vector colineal con un vector unitario,
![]()
Geométricamente, en dos dimensiones tenemos la imagen que se muestra en la figura 4.2, donde i = 1. El vector en el que se gira x (es decir, cuál es u y cuál es v) depende de la elección del signo en ![]() . La elección que se hizo da como resultado el
. La elección que se hizo da como resultado el ![]() que se muestra en la figura y, a partir de la figura, se puede ver que esto es correcto. Tenga en cuenta que
que se muestra en la figura y, a partir de la figura, se puede ver que esto es correcto. Tenga en cuenta que
![]()
Si se hace la elección opuesta, obtenemos el ![]() que se muestra. En el caso bidimensional simple, esto equivale a invertir nuestra elección de u y v.
que se muestra. En el caso bidimensional simple, esto equivale a invertir nuestra elección de u y v.
 18.15.38.png)
Figura 4.2 Reflexión de x aobre v (o ![]() ) y sobre u.
) y sobre u.
Por supuesto, para lograr esta rotación especial, primero elegimos un vector apropiado sobre el cual reflejar nuestro vector dado, y luego realizamos la rotación.
4.3.5 Traslaciones: coordenadas homogéneas
Una traslación de un vector es una transformación relativamente simple en la que el vector se transforma en un vector paralelo. Implica un tipo de suma de vectores. Las rotaciones, como hemos visto, y otras transformaciones geométricas como el corte, como hemos indicado, implican la multiplicación por una matriz apropiada. En aplicaciones donde se van a realizar varias transformaciones geométricas, sería conveniente que las traslaciones también pudieran realizarse mediante multiplicación de matrices. Esto se puede hacer usando coordenadas homogéneas.
Las coordenadas homogéneas, que forman el sistema de coordenadas naturales para la geometría proyectiva, tienen una relación muy simple con las coordenadas cartesianas.
El punto con coordenadas cartesianas (x1, x2,..., xd) se representa en forma homogénea coordenadas como ![]() , donde, para
, donde, para ![]() arbitrario
arbitrario
no igual a cero, ![]() y así sucesivamente. Debido a que el punto es el mismo, los dos diferentes los símbolos representan lo mismo, y tenemos
y así sucesivamente. Debido a que el punto es el mismo, los dos diferentes los símbolos representan lo mismo, y tenemos
![]()
Alternativamente, la coordenada del hiperplano se puede agregar al final, y tenemos
![]()
Cada valor de ![]() corresponde a un hiperplano en el sistema de coordenadas cartesiano ordinario. La opción más común es
corresponde a un hiperplano en el sistema de coordenadas cartesiano ordinario. La opción más común es ![]() = 1, por lo que
= 1, por lo que ![]() .
.
El plano especial ![]() no tiene significado en el sistema cartesiano, pero en geometría proyectiva corresponde a un hiperplano en el infinito.
no tiene significado en el sistema cartesiano, pero en geometría proyectiva corresponde a un hiperplano en el infinito.
Podemos realizar fácilmente la traslación ![]() representando primero el punto x como
representando primero el punto x como ![]() y luego multiplicando por la matriz (d + 1) × (d + 1)
y luego multiplicando por la matriz (d + 1) × (d + 1)
 18.32.35.png)
Usaremos el símbolo xh para representar el vector de coordenadas homogéneas correspondientes:
![]()
Debemos tener cuidado de distinguir el punto x del vector que representa el punto. En coordenadas cartesianas, hay una correspondencia natural y el símbolo x que representa un punto también puede representar el vector ![]() .
.
El vector de coordenadas homogéneas del resultado T xh corresponde a las coordenadas cartesianas de ![]() , que es el resultado deseado. Las coordenadas homogéneas se utilizan ampliamente en gráficos por computadora no solo para las transformaciones geométricas ordinarias sino también para las transformaciones proyectivas, que modelan las propiedades visuales.
, que es el resultado deseado. Las coordenadas homogéneas se utilizan ampliamente en gráficos por computadora no solo para las transformaciones geométricas ordinarias sino también para las transformaciones proyectivas, que modelan las propiedades visuales.
4.4 Transformación Householder (reflexiones)
Hemos discutido brevemente las transformaciones geométricas que reflejan un vector a través de otro vector. Ahora consideramos algunas propiedades y usos de estas transformaciones.
Considere el problema de reflejar x a través del vector v. Como antes, asumimos que u y v son vectores ortonormales y que x se encuentra en un espacio generado por u y v, y x = c1u + c2v. Forma la matriz
![]()
y note que
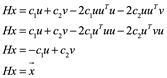
como en la ecuación ![]() . La matriz H es un reflector; ha transformado x en su reflejo
. La matriz H es un reflector; ha transformado x en su reflejo ![]() sobre v.
sobre v.
Una reflexión también se denomina reflexión transformación de Householder, y la matriz H se denomina matriz de reflector de Householder. Es una transformación lineal del espacio que consiste en una reflexión pura con respecto a un plano. Viene definida por una matriz de dimensión tal que para cualquier vector de dimensión N se cumple que es la reflexión de respecto a un plano. Las matrices de transformación de Householder tienen varias propiedades que hacen que su uso en algoritmos matemáticos sea muy ventajoso. En concreto, el ser iguales a su propia inversa ahorra numerosos cálculos por no tener que invertirlas. El hecho de ser ortogonales las hace idóneas para el cálculo de matrices semejantes. Las siguientes propiedades de H son inmediatas:

4.4.1 Poner a cero todos los elementos menos uno en un vector
La utilidad de las reflexiones Householder resulta del hecho de que es fácil construir una reflexión que transforme un vector x en un vector ![]() que tiene ceros en todas menos una posición, como en la ecuación
que tiene ceros en todas menos una posición, como en la ecuación
![]() .
.
Para construir el reflector de x en ![]() , primero necesitamos determinar un vector v como en la Figura 4.2 sobre el cual reflejar x. Ese vector es simplemente
, primero necesitamos determinar un vector v como en la Figura 4.2 sobre el cual reflejar x. Ese vector es simplemente
![]()
Como ![]() , conocemos
, conocemos ![]() dentro del signo; es decir,
dentro del signo; es decir,
![]()
Elegimos el signo para no agregar cantidades de signos diferentes y posiblemente magnitudes similares. Por lo tanto, tenemos
![]()
Lo normalizamos para obtener
![]()
y finalmente formar
![]()
Ejemplo 1: Considere, por ejemplo, el vector
![]()
En el que deseamos transformar
![]()
Nosotros tenemos
![]()
entonces formamos el vector
![]()
Entonces del reflector Householder
![]()

para producir Hx = (−4, 0, 0, 0, 0) o Px = (−4, 0, 0, 0, 0).
En WolframAlpha:
IdentityMatrix[5]- [2(1/sqrt(56)^2)](7,1,2,1,1)Transpose(7,1,2,1,1)
 21.43.39.png)
(1/28){{-21,-7,-14,-7,-7},{-7,27,-2,-1,-1},{-14,-2,24,-2,-2},{-7,-1,-2,27,-1},{-7,-1,-2,-1,27}}
 21.54.29.png)
{3,1,2,1,1}.{{-3/4, -1/4, -1/2, -1/4, -1/4}, {-1/4, 27/28, -1/14, -1/28, -1/28}, {-1/2, -1/14, 6/7, -1/14, -1/14}, {-1/4, -1/28, -1/14, 27/28, -1/28}, {-1/4, -1/28, -1/14, -1/28, 27/28}}
 22.27.52.png)
Hx = (−4, 0, 0, 0, 0)
Householder (1953) consideró por primera vez la matriz que ahora lleva su nombre en las primeras páginas de su libro. Una transformación Householder de un vector v es su reflejo con respecto a un plano (o hiperplano) a través del origen representado por su vector normal v de longitud unitaria ![]() , que se puede encontrar como
, que se puede encontrar como
![]()
donde ![]() es la proyección de x sobre v. En general, la proyección de x sobre cualquier vector u es
es la proyección de x sobre v. En general, la proyección de x sobre cualquier vector u es
![]()
El reflejo de x puede considerarse como una transformación lineal representada por una matriz P aplicada a x (P se usa en lugar de H y x’ en lugar de 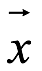 ):
):
![]()
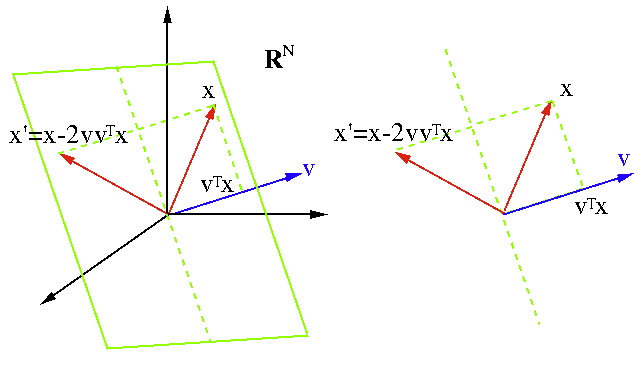
Obviamente P es simétrica
![]()
y también es la inversa de la suya:
Donde ![]() es la matriz Householder
es la matriz Householder
![]()
Por tanto tenemos
![]()
Ejemplo 2: Una matriz A es una matriz ortogonal si
![]()
donde ![]() es la transpuesta de A e I es la matriz identidad. En particular, una matriz ortogonal siempre es invertible y
es la transpuesta de A e I es la matriz identidad. En particular, una matriz ortogonal siempre es invertible y
![]()
En forma de componente,
![]()
Esta relación hace que las matrices ortogonales sean particularmente fáciles de calcular, ya que la operación de transposición es mucho más simple que calcular una inversa.
Por ejemplo,
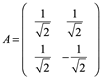
Verifique ![]()
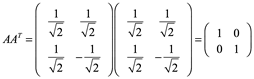
Las filas de una matriz ortogonal son una base ortonormal. Es decir, cada fila tiene una longitud de uno y son mutuamente perpendiculares. Del mismo modo, las columnas también son una base ortonormal. De hecho, dada cualquier base ortonormal, la matriz cuyas filas son esa base es una matriz ortogonal. Automáticamente ocurre que las columnas son otra base ortonormal.
Las matrices ortogonales son precisamente aquellas matrices que preservan el producto interno.
Ejemplo 3: Para la siguiente matriz encuentre a y b para que sea matriz ortogonal.
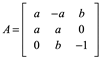
Para que sea ortogonal la matriz:
![]()
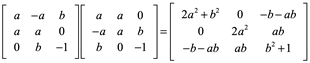
Entonces igualamos
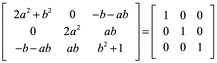
En la segunda fila tercer columna ab=0, necesariamente b=0
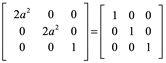
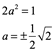
Tomando la solución positiva para +a, se tiene la matriz ortogonal sustituyendo los valores para a y b:
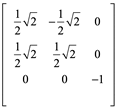
Si se realiza el producto interno entre vectores filas y columnas se podrá verificar que son ortogonales y ortonormales.
Ejemplo 4: Demostrar que A es matriz ortogonal, si estos son los vectores filas de la matriz x1=(0,-1,0); x2=(1,0,0) y x3=(0,0,-1).
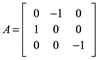
![]()
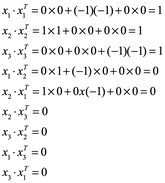
Se demostró que se trata de una matriz ortogonal.
4.5 Proceso de ortonormalización de Gram - Schmidt
Es posible transformar cualquier base en ![]() (no ortogonal y, por lo tanto, no ortonormal) en una base ortonormal usando el proceso de ortonormalización de Gram – Schmidt. Este método fue desarrollado por Jorgen Gram (1850-1916), actuario danés, y Erhardt Schmidt (1876-1959), matemático alemán.
(no ortogonal y, por lo tanto, no ortonormal) en una base ortonormal usando el proceso de ortonormalización de Gram – Schmidt. Este método fue desarrollado por Jorgen Gram (1850-1916), actuario danés, y Erhardt Schmidt (1876-1959), matemático alemán.
Las fórmulas para este proceso incluyen normalizaciones (vectores unitarios), así como proyecciones de un vector sobre otro para obtener vectores ortogonales.
Consideremos el proceso para n = 3.
Sean los vectores ![]() ,
, ![]() y
y ![]() una base de
una base de ![]() . Obtendremos una base ortonormal a partir de estos vectores.
. Obtendremos una base ortonormal a partir de estos vectores.
Primer paso.
Obtener un primer vector unitario  :
:
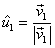
Segundo paso.
Obtener un vector 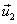 ortogonal a
ortogonal a 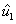 :
:
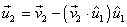
Tercer paso.
Normalizar 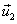 :
:
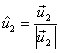
Cuarto paso.
Obtener un vector 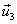 ortogonal a
ortogonal a 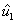 y a
y a 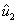 :
:
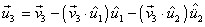
Quinto paso.
Normalizar 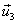 :
:
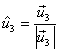
Ejemplo 5: Considere los vectores 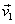 = (1, 0, 1),
= (1, 0, 1), 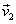 = (0, 1, 1) y
= (0, 1, 1) y 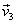 = (1, 0, 0) base de
= (1, 0, 0) base de 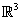 . Transformar esta base en una base ortonormal por el proceso de Gram – Schmidt.
. Transformar esta base en una base ortonormal por el proceso de Gram – Schmidt.

Primer paso:
Obtener un primer vector unitario 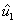 :
:
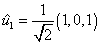
Segundo paso:
Obtener un vector  ortogonal a
ortogonal a  :
:
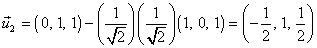
Tercer paso:
Normalizar 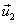 :
:
Cuarto paso:
Obtener un vector  ortogonal a
ortogonal a 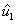 y a
y a 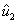 :
:
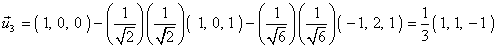
Quinto paso.
Normalizar 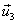 :
:
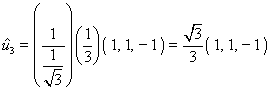
Finalmente, el conjunto de vectores 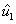 ,
, 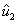 , y
, y 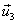 es una base ortonormal de
es una base ortonormal de 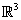 .
.
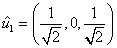
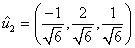
 15.08.24.png)
Ejemplo 6: Calcule la base ortonormal para
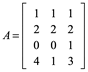
WolframAlpha: orthonormal basis for {[1,1,1],[2,2,2],[0,0,1],[4,1,3]}
 21.35.14.png)
 21.35.48.png)
Proceso de Gram-Schmidt
Sea ![]() una base de un subespacio W de
una base de un subespacio W de ![]() y definimos los pasos siguientes:
y definimos los pasos siguientes:
|
W1=espacio (x) |
|
W2=espacio(x1,x2) |
|
W3=espacio(x1,x2,x3) |
|
|
|
Wn=espacio |
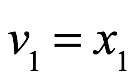
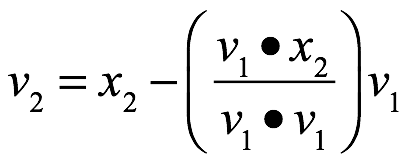
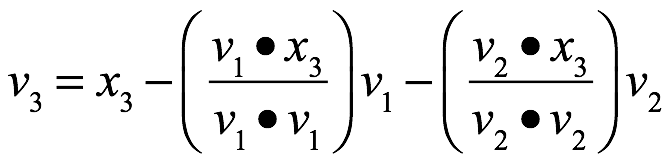

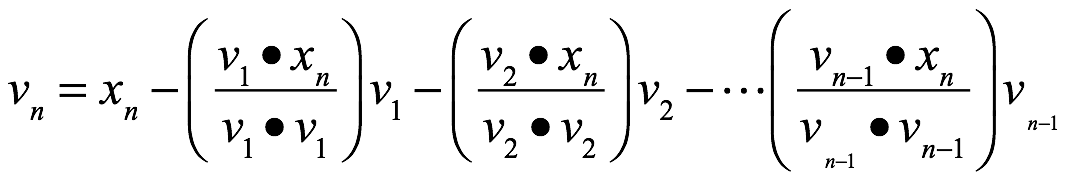
![]() entonces
entonces ![]() es una base ortogonal de Wi. En particular
es una base ortogonal de Wi. En particular ![]() es una base ortogonal de W.
es una base ortogonal de W.
4.6 Transformaciones de Givens (rotaciones)
Hemos discutido brevemente las transformaciones geométricas que rotan un vector de tal manera que un elemento especificado se convierte en 0 y solo se cambia otro elemento en el vector. Un método de este tipo puede ser particularmente útil si solo se dispone de una parte de la matriz a transformar. Estas transformaciones se denominan transformaciones de Givens, rotaciones de Givens o, a veces, transformaciones de Jacobi.
La idea básica de la rotación, que es un caso especial de las rotaciones discutidas, se puede ver en el caso de un vector de longitud 2. Dado el vector x = (x1, x2), deseamos rotarlo a ![]() . Al igual que con una reflexión, en la rotación también tenemos
. Al igual que con una reflexión, en la rotación también tenemos ![]() . Geométricamente, tenemos la imagen que se muestra en la Fig. 4.3.
. Geométricamente, tenemos la imagen que se muestra en la Fig. 4.3.
 18.37.50.png)
Figura 4.3 Rotación de x sobre un eje de coordenadas
Es fácil ver que la matriz ortogonal
![]()
realizará esta rotación de x si ![]() y
y ![]() , donde
, donde![]() . Esta es la misma matriz que en la ecuación
. Esta es la misma matriz que en la ecuación ![]() , excepto que
, excepto que
la rotación es en la dirección opuesta. Observe que θ no es relevante; solo necesitamos números reales c y s tales que ![]() .
.
Tenemos
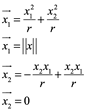
es decir
![]()
4.7 Poner a cero un elemento en un vector
Al igual que con la reflexión Householder que transforma un vector
![]()
En un vector
![]()
es fácil construir una rotación Givens que transforme x en
![]()
Podemos construir una matriz ortogonal Gpq similar a la que se muestra en la ecuación ![]() que transformará el vector
que transformará el vector
![]()
En
![]()
La matriz ortogonal que hará esto es
 17.17.54.png)
donde las entradas en las filas y columnas pth y qth son
![]()
y
![]()
Donde ![]() . Una matriz de rotación es lo mismo que una matriz de identidad con cuatro elementos cambiados.
. Una matriz de rotación es lo mismo que una matriz de identidad con cuatro elementos cambiados.
Considerando que x es la p-ésima columna en una matriz X, podemos ver fácilmente que GpqX da como resultado una matriz con un cero en el q-ésimo elemento de la p-ésima columna, y todas excepto las p-ésima y q-ésima filas y columnas de GpqX son iguales a los de X.
4.8 Rotaciones dadas que conservan la simetría
Si X es una matriz simétrica (es una matriz cuadrada, la cual tiene la característica de ser igual a su traspuesta), podemos preservar la simetría mediante una transformación de la forma QTXQ, donde Q es cualquier matriz ortogonal. Los elementos de una matriz de rotación Givens que se utiliza de esta forma y con el objetivo de formar ceros en dos posiciones en X simultáneamente se determinarían de la misma forma anterior, pero los elementos en sí no serían los mismos. Lo ilustramos a continuación, mientras que al mismo tiempo consideramos el problema de transformar un valor en algo distinto de cero.
4.8.1 Da rotaciones para transformar a otros valores
Considere una matriz simétrica X que deseamos transformar en la matriz simétrica ![]() que tiene todas las filas y columnas excepto la pth y la qth iguales a las de X, y queremos un valor especificado en la (p, p)th posición de
que tiene todas las filas y columnas excepto la pth y la qth iguales a las de X, y queremos un valor especificado en la (p, p)th posición de ![]() , digamos
, digamos ![]() . Buscamos una matriz de rotación G tal que
. Buscamos una matriz de rotación G tal que ![]() . Tenemos
. Tenemos
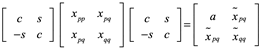
y
![]()
Por lo tanto
![]()
Se escribe ![]() (la tangente), podemos tener la cuadrática
(la tangente), podemos tener la cuadrática
![]()
Con raíces
![]()
Las raíces son reales si y solo si
![]()
Si las raíces de la ecuación cuadrática son reales, elegimos la no negativa. Luego formamos
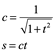
La matriz de rotación G formada por c y s transformará X en ![]() .
.
4.8.2 Rotaciones rápidas Givens
A menudo, en las aplicaciones, necesitamos realizar una sucesión de transformaciones de Givens. El número total de cálculos se puede reducir mediante una sucesión de "rotaciones rápidas de Givens". Escribimos la matriz Q en la ecuación ![]() como CT,
como CT,
![]()
y en lugar de trabajar con matrices como Q, que requieren cuatro multiplicaciones y dos sumas, trabajamos con matrices como T, que involucran tangentes, que requieren solo dos multiplicaciones y dos sumas. Después de varios cálculos con tales matrices, las matrices diagonales de la forma de C se acumulan y se multiplican juntas.
Los elementos diagonales en las matrices C acumuladas en las rotaciones rápidas de Givens pueden llegar a ser muy diferentes en valores absolutos, por lo que para evitar una pérdida excesiva de precisión, generalmente es necesario cambiar la escala de los elementos periódicamente.
4.9 Factorización de matrices
A menudo es útil representar una matriz A en forma factorizada,
A = BC
donde B y C tienen algunas propiedades deseables especificadas, como ser ortogonal o triangular. Generalmente buscamos B y C de manera que B y C tengan propiedades útiles para algún aspecto particular del problema que se aborda.
La mayoría de los métodos directos para resolver sistemas lineales se basan en factorizaciones (o, de manera equivalente, "descomposiciones") de la matriz de coeficientes. Las factorizaciones matriciales también se realizan por razones distintas de la resolución de un sistema lineal, como en el autoanálisis.
Nótese una indeterminación en la factorización A = BC; si B y C son factores de A, entonces también lo son −B y −C. Esta indeterminación incluye no solo los negativos de las matrices en sí, sino también los negativos de varias filas y columnas debidamente elegidas. De forma más general, si D y E son matrices tales que DE = Im, donde m es el número de columnas en B y filas en C, entonces A = BDEC, por lo que A se puede factorizar como el producto de BD y EC. Por tanto, en general, una factorización no es única. Sin embargo, si se imponen restricciones a ciertas propiedades de los factores, entonces, bajo esas restricciones, las factorizaciones pueden ser únicas. Además, si se da un factor, el otro factor puede ser único. (Por ejemplo, en el caso de matrices no singulares, podemos ver esto tomando la inversa). Las transformaciones invertibles dan como resultado una factorización de una matriz. Para una matriz B de n×k, si D es una matriz de k×n tal que BD = In, entonces una matriz A de n×m dada se puede factorizar como A = BDA = BC, donde C = DA.
En las próximas secciones presentaremos las factorizaciones LU, LDU, QR y Cholesky. También describiremos la factorización de raíz cuadrada, aunque utiliza valores propios, que requieren métodos iterativos.
Las factorizaciones matriciales se realizan generalmente mediante una secuencia de transformaciones de rango completo y sus inversas.
4.9.1 Factorizaciones LU y LDU
Para cualquier matriz (ya sea cuadrada o no) que se pueda expresar como LU, donde L es triangular inferior (o trapezoidal inferior) y U es triangular superior (o trapezoidal superior), el producto LU se denomina factorización LU. También generalmente restringimos L o U para que tengan 0 o 1 en la diagonal. Si existe una factorización LU, está claro que se puede hacer que L o U (pero no necesariamente ambos) tengan solo 1 y 0 en su diagonal.
Si existe una factorización LU, se puede hacer que tanto la matriz triangular inferior, L, como la matriz triangular superior, U, tengan solo 1 o 0 en sus diagonales (es decir, que sean unidades triangulares inferiores o triangulares superiores) poniendo los productos de cualquier elemento diagonal no unitario en una matriz diagonal D y luego escribiendo la factorización como LDU, donde ahora L y U son matrices triangulares unitarias (es decir, matrices con 1 en la diagonal). Esto se llama factorización de LDU.
Si una matriz no es cuadrada, o si la matriz no es de rango completo, en su descomposición LU, L y/o U pueden tener cero elementos diagonales o serán de forma trapezoidal. Un ejemplo de una matriz singular y su factorización LU es
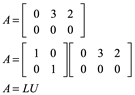
En este caso, U es una matriz trapezoidal superior.
4.9.2 Propiedades: existencia y unicidad
La existencia y unicidad de una factorización LU (o factorización LDU) son cuestiones interesantes. No es necesario ni suficiente que una matriz no sea singular para que tenga una factorización LU. El ejemplo anterior muestra la factorización LU para una matriz que no es de rango completo. Además, una matriz de rango completo no necesariamente tiene una factorización LU, como veremos a continuación.
Un ejemplo de una matriz no singular que no tiene una factorización LU es una matriz de identidad con filas o columnas permutadas:
![]()
Las condiciones para la existencia de una factorización LU no son tan fáciles de enunciar, pero en la práctica, como veremos, la pregunta no es muy relevante. Primero, sin embargo, consideraremos una matriz que está garantizada para tener una factorización LU y mostraremos un método para obtenerla.
Una condición suficiente para que una matriz A de n×m tenga una factorización LU es que para k = 1, 2,. . . , min(n, m), cada k×k submatriz principal de A sea
no singular.
La demostración es por construcción. Suponemos que todas las submatrices principales son no singulares. Esto significa que ![]() , por lo que existe la matriz gaussiana G11.
, por lo que existe la matriz gaussiana G11.
La eliminación gaussiana a menudo se realiza secuencialmente en la diagonal.
elementos de una matriz.
Multiplicamos A por G11, obteniendo
![]()
en el que ![]() para i = 2,. . . , n y
para i = 2,. . . , n y ![]() (de lo contrario, la submatriz principal 2×2 sería singular, que por supuesto no lo es).
(de lo contrario, la submatriz principal 2×2 sería singular, que por supuesto no lo es).
Como a (1) 22 = 0, existe la matriz gaussiana G22, y ahora multiplicamos G11A por G22, obteniendo
![]()
en el que ![]() para i = 3,. . . , n y una
para i = 3,. . . , n y una ![]() como antes. (Todo
como antes. (Todo ![]() no se modifican).
no se modifican).
Continuamos de esta manera por k = min(n, m) pasos, para obtener
![]()
en el que ![]() es triangular superior y la matriz
es triangular superior y la matriz ![]() es triangular inferior porque cada matriz en el producto es triangular inferior.
es triangular inferior porque cada matriz en el producto es triangular inferior.
Además, cada matriz del producto ![]() es no singular, y la matriz
es no singular, y la matriz ![]() es triangular inferior. Completamos la factorización multiplicando ambos lados de la ecuación
es triangular inferior. Completamos la factorización multiplicando ambos lados de la ecuación ![]() por:
por:
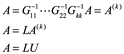
Por tanto, vemos que una matriz A de n m tiene una factorización LU si para k =
1, 2,. . . , min(n, m), cada submatriz principal k×k de A es no singular.
Una matriz cuadrada no invertible se dice que es singular o degenerada. Una matriz es singular si y sólo si su determinante es nulo. Caso contrario es no singular.
Los elementos de la diagonal de ![]() , es decir, U, son todos 1; por lo tanto, notamos
, es decir, U, son todos 1; por lo tanto, notamos
una propiedad útil para matrices cuadradas. Si la matriz es cuadrada (k=n), entonces...
![]()
Por lo tanto, la reducción hacia adelante es equivalente a expresar A como LU,
![]()
En este caso, los elementos diagonales de la matriz triangular inferior L en la factorización LU son todos 1 según el método de construcción, y si A es cuadrada
![]()
Incluso si las submatrices principales de una matriz no son no singulares, la matriz puede tener una descomposición LU, y puede ser calculable usando una secuencia de matrices gaussianas como hicimos anteriormente. Considere, por ejemplo,
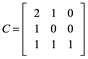
cuyo 0 en la posición (2, 2) viola la condición de no singularidad. Después de tres pasos gaussianos como arriba, tenemos
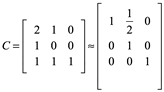
De lo que obtenemos
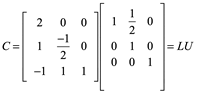
También notamos que
![]()
Se garantiza que el método de construcción de la factorización LU descrito anteriormente funciona en el caso de matrices con todas las submatrices principales no singulares y en algunos otros casos, como para C. El hecho de que C no sea singular no es suficiente para asegurar que el proceso funcione o incluso que exista la factorización. (Como indicamos anteriormente, las condiciones suficientes son bastante complicadas, pero no importa mucho en la práctica).
Si la matriz no es de rango completo, ya que se están formando las matrices gaussianas, en algún punto el elemento diagonal ![]() será cero, por lo que no se puede formar la matriz
será cero, por lo que no se puede formar la matriz ![]() . Para tales casos, simplemente formamos una fila de ceros en la matriz triangular inferior y pasamos al siguiente elemento diagonal. Incluso si la matriz es de rango completo, pero no todas las submatrices principales son de rango completo, encontraríamos este mismo tipo de problema. En las aplicaciones, podemos abordar estos dos problemas de manera similar, utilizando una técnica de pivote.
. Para tales casos, simplemente formamos una fila de ceros en la matriz triangular inferior y pasamos al siguiente elemento diagonal. Incluso si la matriz es de rango completo, pero no todas las submatrices principales son de rango completo, encontraríamos este mismo tipo de problema. En las aplicaciones, podemos abordar estos dos problemas de manera similar, utilizando una técnica de pivote.
La factorización LU fue creada por Alan M. Turing (1912-1954) en un artículo titulado “Rounding off error in matriz proceses” publicado en 1948[1].
![]()
Ejemplifiquemos esto, así como 24=2x3x4 es una factorización de un número natural, Las matrices pueden representarse como productos de otras matrices. Consideremos un sistema de ecuaciones líneas Ax=b, donde A es la matriz cuadrada nxn. La idea es utilizar la eliminación gaussiana que implícitamente factorizan a A, y esto nos permite solucionar el sistema dado. En seguida realizamos un ejemplo para:
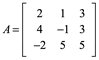
Reducir por renglones A:
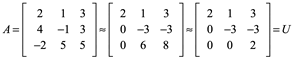
Observe que este elemento U es una matriz triangular superior. Mientras que L es una matriz triangular inferior unitaria. Es decir, L tiene la forma de:
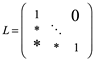
Para este caso
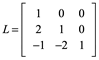
Con ceros por arriba y unos en la diagonal principal. Compruebe sus resultados con A=LU. Apoyándonos en WolframAlpha teclee “Givens Transformations matrix”.
 12.09.52.png)
Si la reducción por renglones (gaussiana) de A invertible puede expresarse como una factorización LU del tipo A=LU, entonces esta factorización es única.
Ejemplo 7. Empleando la factorización LU resolver los sistemas de ecuaciones Ax=b siguiente:
![]()
1) Un sistema Ax=b
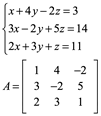
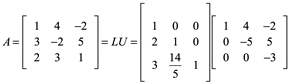
Paso uno Ly=b
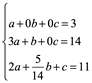
Se resuelve
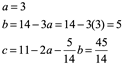
![]()
Ahora
Ux=b
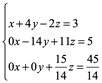
Resolvemos de igual manera:
![]()
Solución de este sistema de ecuaciones (x,y,z) es (1,2,3). Puede verificarlo.
4.9.3 Factorización QR
Una factorización muy útil de una matriz es el producto de una matriz ortogonal y una matriz triangular superior con elementos diagonales no negativos. Dependiendo de la forma de A, las formas de los factores pueden variar, e incluso la definición de los factores en sí puede expresarse de manera diferente.
Sea A una matriz n×m y suponga
![]()
donde Q es una matriz ortogonal (calculado por el proceso Gram-Schmidt) y R es una matriz triangular o trapezoidal superior con elementos diagonales no negativos. Esto se llama factorización QR de A. En la mayoría de las aplicaciones, n ≥ m, pero si este no es el caso, todavía tenemos una factorización en matrices similares.
La factorización QR es útil para muchas tareas en álgebra lineal. Se puede utilizar para determinar el rango de una matriz, para extraer Eingenvalores y Eigenvectores, para formar la descomposición de valores singulares, y para mostrar varias propiedades teóricas de las matrices. La factorización QR es particularmente útil en cálculos para sistemas sobre determinados y en otros cálculos que involucran matrices no cuadradas.
Ejemplo 7: de una factorización QR, dada una matriz A, vectores columna linealmente independientes, son una base de un subespacio W.
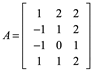
Primer paso, aplicar el proceso de Gran-Schmidt construir una matriz Q ortonormal:
Sea ![]() una base de un subespacio W de
una base de un subespacio W de ![]() y definimos los pasos siguientes:
y definimos los pasos siguientes:
|
W1=espacio (x) |
|
W2=espacio(x1,x2) |
|
W3=espacio(x1,x2,x3) |
|
|
|
Wn=espacio |
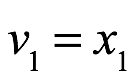
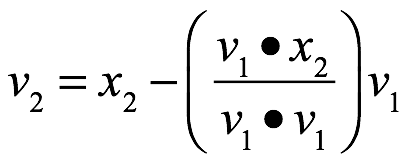
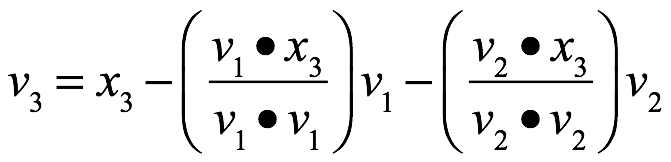

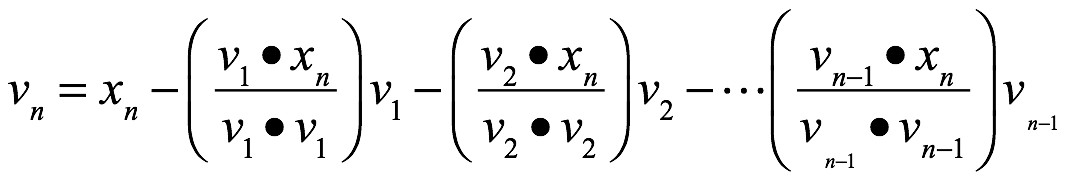
![]() entonces
entonces ![]() es una base ortogonal de Wi. En particular
es una base ortogonal de Wi. En particular ![]() es una base ortogonal de W.
es una base ortogonal de W.
Para W1:
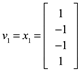
Para W1:
![]()
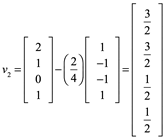
Para W3:
![]()
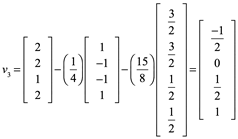
La base ortogonal ![]() de W, para finalmente tener una matriz base ortonormal debemos cada base
de W, para finalmente tener una matriz base ortonormal debemos cada base ![]() dividirla entre su norma:
dividirla entre su norma:
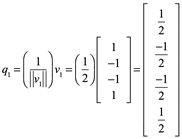
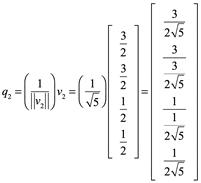
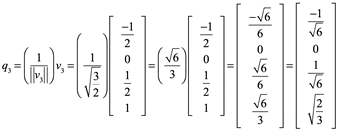
Así que ![]() es una base ortonormal de W.
es una base ortonormal de W.
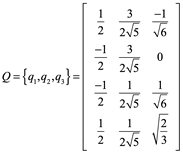
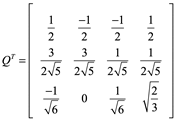
![]()
Para encontrar R, puesto que ![]()
![]()
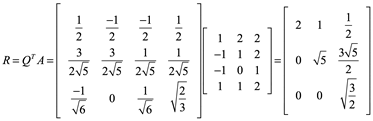
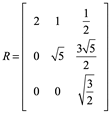
Comprobar A=QR
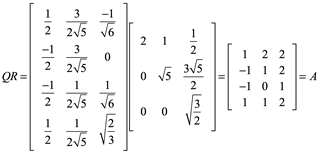
 17.02.20.png)
___________
Givens Transformations matrix
 22.46.11.png)
Referencias
[1] http://www.libertadacademica.com/PDFeditorial1/PDF25/ele/
______________________________
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Lizbeth Guadalupe Villalon Magallan
Mónica Rico Reyes
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán