Texto universitario

_____________________________
Módulo 5. Soluciones a sistemas lineales
Uno de los problemas más comunes en la computación numérica es resolver el sistema lineal Ax = b; es decir, para A y b dados, encontrar x tal que se cumpla la ecuación. Se dice que el sistema es consistente si existe tal x, y en ese caso una solución x puede escribirse como ![]() , donde
, donde ![]() es la inversa de A. Si A es cuadrada y de rango completo, podemos escribir la solución como
es la inversa de A. Si A es cuadrada y de rango completo, podemos escribir la solución como ![]() . Nosotros nunca calcularíamos
. Nosotros nunca calcularíamos ![]() solo para poder multiplicarlo por b para formar la solución
solo para poder multiplicarlo por b para formar la solución ![]() .
.
Dos temas que discutimos tienen mayor relevancia en los cálculos para aplicaciones científicas. La primera es cómo evaluar las dificultades numéricas esperadas para resolver un problema específico. Un problema específico se compone de una tarea y datos, o entrada de la tarea. Algunas tareas son naturalmente más difíciles que otras; por ejemplo, generalmente es más difícil resolver un problema de optimización restringido que resolver un sistema de ecuaciones lineales. Sin embargo, algunos problemas de optimización restringida pueden ser muy "pequeños" e incluso tener una solución simple de forma cerrada; mientras que un sistema de ecuaciones lineales puede ser muy grande y estar sujeto a graves errores de redondeo. Para cualquier tarea específica, puede haber formas de evaluar la "dificultad" de una entrada específica. Una medida de dificultad es un "número de condición", y discutimos en seguida un número de condición para la tarea de resolver un sistema lineal.
Otro tema ilustrado por las técnicas discutidas es la diferencia entre métodos directos y métodos iterativos. Los métodos para factorizar una matriz son métodos directos; es decir, hay una secuencia fija de operaciones (posiblemente con algunos pivotes en el camino) que produce la solución. Los métodos iterativos no tienen un número fijo predeterminado de pasos; más bien, deben tener una regla de detención que dependa de los propios pasos. La mayoría de los métodos de optimización son ejemplos de métodos iterativos. Todos los métodos para obtener valores propios (para matrices cuadradas generales mayores de 4 × 4) son necesariamente iterativos.
Un método iterativo se caracteriza por una secuencia de soluciones parciales o aproximadas, que indico con un superíndice entre paréntesis: s(0), s(1), s(2),... Es necesario un punto de partida. Normalmente lo indexo como "(0)". El algoritmo iterativo es esencialmente una regla para calcular s(k) dado s(k − 1).
También es necesario un criterio de parada. La solución parcial en cualquier punto de la secuencia a menudo consta de varias partes; por ejemplo, en un problema de optimización, hay dos partes, el valor de la variable de decisión y el valor de la función objetivo. La regla de detención puede basarse en la magnitud del cambio en una o más partes de la solución. Por supuesto, un criterio de detención basado simplemente en el número de también es posible realizar iteraciones y, de hecho, suele ser una buena idea además de cualquier otro criterio de parada.
Discutimos métodos directos para resolver sistemas de ecuaciones lineales. Un método directo utiliza un número fijo de cálculos que, en aritmética exacta, conducirían a la solución. También podemos referirnos a los pasos en un método directo como "iteraciones"; pero hay un límite fijo en el número de ellos que depende solo del tamaño de la entrada.
Los métodos iterativos a menudo funcionan bien para matrices muy grandes y/o dispersas. Otro principio general en los cálculos numéricos es que una vez que se ha obtenido una solución aproximada (en la computación numérica, casi todas las soluciones son aproximadas), a menudo es útil ver si la solución se puede mejorar. Este principio está bien ilustrado por el "refinamiento iterativo" de una solución a un sistema lineal. El refinamiento iterativo es un método iterativo, pero el método que produce la aproximación inicial puede ser un método directo.
5.1 Condición de las matrices
Se dice que los datos están "mal acondicionados" para un problema o cálculo en particular si es probable que los datos causen dificultades en los cálculos, como una gran pérdida de precisión. De manera más general, el término "mal condicionado" se aplica a un problema en el que pequeños cambios en la entrada dan como resultado grandes cambios en la salida. En el caso de un sistema lineal
Ax = b,
el problema de resolver el sistema está mal condicionado si pequeños cambios en algunos elementos de A o b causarán grandes cambios en la solución x. El concepto de mal condicionamiento es una generalización heurística de la propiedad de mal planteamiento de Hadamard.
Considere, por ejemplo, el sistema de ecuaciones
1.000x1 + 0.500x2 = 1.500,
0.667x1 + 0.333x2 = 1.000.
Se ve fácilmente que la solución es x1 = 1.000 y x2 = 1.000.
Ahora considere un pequeño cambio en el lado derecho:
1. 000x1 + 0. 500x2 = 1. 500,
0. 667x1 + 0. 333x2 = 0. 999.
Este sistema tiene la solución x1 = 0.000 y x2 = 3.000. Ese es un cambio relativamente grande.
Alternativamente, considere un pequeño cambio en uno de los elementos de la matriz de coeficientes:
1. 000x1 + 0. 500x2 = 1. 500,
0. 667x1 + 0. 334x2 = 1. 000.
La solución ahora es x1 = 2.000 y x2 = −1.000; nuevamente, un cambio relativamente grande.
En ambos casos, pequeños cambios del orden de 10−3 en la entrada (los elementos de la matriz de coeficientes o el lado derecho) dan como resultado cambios relativamente grandes (del orden de 1) en la salida (la solución). Resolver el sistema (cualquiera de ellos) es un problema mal condicionado cuando nuestras escalas relevantes son de orden 3.
La naturaleza de los datos que causan el mal condicionamiento depende del tipo de problema. El caso anterior se puede considerar como un problema geométrico para determinar el punto de intersección de dos líneas. El problema es que las líneas representadas por las ecuaciones son casi paralelas, como se ve en la figura 5.1, por lo que su punto de intersección es muy sensible a cambios leves en los coeficientes que definen las líneas.
El problema también se puede describir en términos del ángulo entre las líneas. Cuando el ángulo es pequeño, pero no necesariamente 0, nos referimos a la condición como “colinealidad”. (Este término es algo engañoso porque, estrictamente hablando, debería indicar que el ángulo es exactamente 0). En este ejemplo, el coseno del ángulo entre las líneas, de la ecuación (2.54), es 1− 2×10−7. En general, la colinealidad (o “multicolinealidad”) existe siempre que el ángulo entre cualquier línea (es decir, un vector) y el subespacio abarcado por cualquier otro conjunto de vectores es pequeño.
 17.45.18.png)
Futura 5.1. Líneas casi paralelas: matrices de coeficientes mal acondicionadas, ecuaciones.
5.1.1 Número de condición
Para un problema específico, como resolver un sistema de ecuaciones, podemos cuantificar la condición de la matriz mediante un número de condición. Para desarrollar esta cuantificación para el problema de resolver ecuaciones lineales, considere un sistema lineal Ax = b, con A no singular y b = 0, como se indicó anteriormente. Ahora perturbe ligeramente el sistema agregando una pequeña cantidad, δb, para b, y sea ![]() . El sistema
. El sistema
![]()
tiene una solución ![]() . (Observe que δb y δx no necesariamente representan múltiplos escalares de los vectores respectivos). Si el sistema está bien acondicionado, para cualquier norma razonable, si
. (Observe que δb y δx no necesariamente representan múltiplos escalares de los vectores respectivos). Si el sistema está bien acondicionado, para cualquier norma razonable, si ![]() es pequeño, entonces
es pequeño, entonces ![]() es igualmente pequeña.
es igualmente pequeña.
De ![]() y la desigualdad, para una norma inducida en A, tenemos
y la desigualdad, para una norma inducida en A, tenemos
![]()
Asimismo, debido a que b = Ax, tenemos
![]()
y estas dos ecuaciones juntas implican
![]() Ec. 6.1
Ec. 6.1
Esto proporciona un límite al cambio en la solución ![]() en términos de la perturbación
en términos de la perturbación ![]() .
.
El límite en la Ec. 6.1 nos motiva a definir el número de condición con respecto a la inversión, denotado por κ (·), como
![]()
para A no singular. En el contexto del álgebra lineal, el número de condición con respecto a la inversión es tan dominante en importancia que generalmente nos referimos a él como el “número de condición”. Este número de condición también proporciona un límite en los cambios en los valores propios debido a las perturbaciones de la matriz. (Ese límite en particular tiene más interés teórico que valor práctico). Un número de condición es una medida útil de la condición de A para el problema de resolver un sistema lineal de ecuaciones. Sin embargo, existen otros números de condición útiles en el análisis numérico, como el número de condición para calcular la varianza de la muestra o un número de condición para la raíz de una función.
Podemos escribir la Ec. 6.1 como
![]()
y, siguiendo un desarrollo similar al anterior, escriba
![]()
Estas desigualdades, así como las demás que escribimos en esta sección, son agudas, como podemos ver al dejar A = I.
Debido a que el número de condición es un límite superior en una cantidad que no quisiéramos que fuera grande, un número de condición grande es "malo". Observe que nuestra definición del número de condición no especifica la norma; sólo requiere que la norma sea una norma inducida. (Una definición equivalente no se basa en que la norma sea una norma inducida). A veces especificamos un número de condición con respecto a una norma particular, y así como a veces denotamos una norma específica mediante un símbolo especial, podemos usar un símbolo especial para denotar un número de condición específico. Por ejemplo, ![]() puede denotar el número de condición de A en términos de una norma Lp. La mayoría de las propiedades de los números de condición (pero no sus valores reales) son independientes de la norma utilizada.
puede denotar el número de condición de A en términos de una norma Lp. La mayoría de las propiedades de los números de condición (pero no sus valores reales) son independientes de la norma utilizada.
La matriz de coeficientes
![]()
Su matriz inversa es
![]()
Es fácil ver eso
![]()
y
![]()
Una
![]()
por lo tanto,
![]()
Igualmente,
![]()
y una
![]()
Observe que los números de condición no son exactamente los mismos, pero están cerca. Observe también que los números de condición son del orden de magnitud de la relación entre la perturbación de salida y la perturbación de entrada en esas ecuaciones.
Aunque usamos esta matriz en un ejemplo de mal condicionamiento, estos números de condición, aunque son grandes, no son tan grandes como para causar una preocupación indebida por los cálculos numéricos. De hecho, resolver los sistemas de ecuaciones no causaría problemas a un programa de computadora.
5.2 Eigenvalores y Eigenvectores, propiedades básicas
En este apartado o estudiamos otra rama importante del álgebra lineal, muy diferente
de lo que hemos visto hasta ahora. Los problemas en esta área surgen en muchas aplicaciones en física, economía, estadística y otros campos. La razón principal porque este fenómeno se puede explicar a grandes rasgos como sigue.
Con frecuencia, los estados de un sistema físico pueden describirse mediante un
vector x de n-dimensiones y el cambio de este último en el tiempo por una matriz A n×n, de modo que el estado del sistema en algún momento posterior vendrá dado por el vector y = Ax. A menudo, tales cambios se describen mediante ecuaciones diferenciales, es decir, el vector x es una función vectorial diferenciable desconocida del tiempo que satisface una ecuación de la forma x’ = Ax. Tales ecuaciones diferenciales también conducen a la misma situación básica que queremos explicar para el caso más simple de y = Ax.
Considere el caso bidimensional, para el cual podemos expresar y = Ax como
el par de ecuaciones escalares
![]()
Como muestran estas ecuaciones, generalmente la matriz A mezcla los componentes de x y, en muchos de esos pasos de tiempo (especialmente en casos de dimensiones superiores), esta mezcla puede ser bastante complicada. La pregunta que nos hacemos, por tanto, es si es posible encontrar una nueva base {s1, s2} para R2 en la que tal mezcla no no ocurre, es decir, en el que los componentes se desacoplan y se desarrollan por separado como
![]()
donde λ1 y λ2 son escalares apropiados dependiendo de la matriz A. La respuesta es frecuentemente sí, y conduce a cálculos enormemente simplificados cuando muchos de estos pasos se suceden. Ilustremos este desacoplamiento con un ejemplo.
Ejemplo 1: Un desacoplamiento de coordenadas en la acción de una matriz). Considere la matriz
y su acción sobre un vector arbitrario x. Dejar
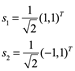
Entonces
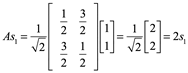
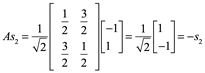
Entonces, si escribimos x e y = Ax en términos de la base {s1, s2} como
![]()
Entonces nosotros obtenemos
![]()
y de esto
![]()
Por tanto, la acción de A sobre las S-componentes de x es una simple multiplicación (ver figura siguiente), mientras que en la base estándar implicaría combinaciones lineales. De manera similar, los S-componente de A2x serían ![]() y
y ![]() , y así sucesivamente para potencias superiores; expresiones mucho más simples que las utilizadas en la base estándar.
, y así sucesivamente para potencias superiores; expresiones mucho más simples que las utilizadas en la base estándar.
 17.17.44.png)
En general, ¿cómo podemos encontrar una base como la del ejemplo anterior? Debemos encontrar {s1, s2} no triviales y λ1 y λ2 correspondientes tales que
![]()
De hecho, en ese caso, sustituyendo
![]()
![]()
en la ecuación y = Ax, obtenemos
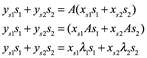
de lo que se sigue que
![]()
Veremos ejemplos más detallados más adelante. Por ahora, solo queremos basar nuestra definición fundamental en las ecuaciones
![]()
que se encuentran en el corazón de toda esta teoría.
Definición de valores propios y vectores propios. Para cualquier matriz A de n×n, un escalar λ se llama valor propio de A (o eigenvalor) si hay un vector s distinto de cero tal que
![]()
Dicho vector s se denomina autovector de A correspondiente o perteneciente a λ. Además, para cada valor propio λ, el vector cero es siempre una solución de la ecuación ![]() , y se denomina vector propio (o eigenvector) de A que pertenece a λ.
, y se denomina vector propio (o eigenvector) de A que pertenece a λ.
La palabra “eigen” en alemán significa “propio” y fue adoptada al inglés, aunque algunos autores usan el valor propio y el vector propio o el valor característico y el vector característico en su lugar. La letra griego lambda ![]() es tradicional en este contexto.
es tradicional en este contexto.
Geométricamente, la Ecuación ![]() expresa el hecho de que un vector propio de una matriz A es un vector distinto de cero cuya dirección es preservada por A, y el valor propio correspondiente es el multiplicador por el cual la matriz escala este vector propio.
expresa el hecho de que un vector propio de una matriz A es un vector distinto de cero cuya dirección es preservada por A, y el valor propio correspondiente es el multiplicador por el cual la matriz escala este vector propio.
La definición se puede generalizar para aplicarla a las transformaciones lineales T: V → V desde cualquier espacio vectorial no trivial a sí mismo, lo cual es importante en casos de dimensión infinita. La definición de matriz es un caso especial más general.
Entonces, ¿cómo resolvemos la ecuación ![]() ? El procedimiento habitual es el siguiente:
? El procedimiento habitual es el siguiente:
Lo reescribimos como
![]()
ya que en esta forma tenemos una ecuación muy parecida a la familiar As = 0, excepto que la matriz A es reemplazada por la matriz A − λI. Recuerde que, para cada λ sea fija, una ecuación homogénea tiene soluciones no triviales sí y solo si su matriz es singular. Por el teorema que dice A es singular sí y solo si | A | = 0. Una matriz cuadrada A es singular sí y solo si su determinante es igual a cero. Esta condición es equivalente a
![]()
Esta es una ecuación para la incógnita λ y se llama ecuación característica de la matriz A. El lado izquierdo de la ecuación se llama polinomio característico de A. La ecuación ![]() no contiene el vector desconocido s y por lo tanto se usa para encontrar los valores propios. Para una matriz n×n, es una ecuación algebraica de grado n. Una vez que se conoce un valor de λ, lo sustituimos en la Ecuación
no contiene el vector desconocido s y por lo tanto se usa para encontrar los valores propios. Para una matriz n×n, es una ecuación algebraica de grado n. Una vez que se conoce un valor de λ, lo sustituimos en la Ecuación ![]() y resolvemos esta última para s por eliminación gaussiana. El conjunto de soluciones de la
y resolvemos esta última para s por eliminación gaussiana. El conjunto de soluciones de la ![]() para un λ dado es Nulo (A − λI) y se llama el espacio propio de A que pertenece a λ.
para un λ dado es Nulo (A − λI) y se llama el espacio propio de A que pertenece a λ.
Ejemplo 1. Una matriz de 2×2 con dos valores propios y dos Eigenspacios dimensionales. Encuentre los eigenvalores y eigenvectores de
![]()
La ecuación característica correspondiente es
![]()
Expandiendo el determinante, obtenemos
![]()
![]()
Por tanto, los valores propios son λ1 = −1 y λ2 = 3.
Para encontrar los eigenvectores, sustituimos estos eigenvalores, uno a la vez, en la ecuación ![]() y resolvemos para el vector desconocido s.
y resolvemos para el vector desconocido s.
Comencemos con λ1= −1. Entonces la ecuación ![]() se convierte en
se convierte en
![]()
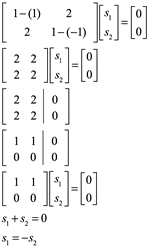
De acuerdo con el ecuación:
![]()
Dejando ![]() en
en ![]() Nosotros encontramos que
Nosotros encontramos que ![]() es un eigenvector de la matriz
es un eigenvector de la matriz ![]() asociado con el eigenvalor
asociado con el eigenvalor ![]() .
.
![]()
Las soluciones de esta ecuación son de la forma ![]() . Así, los eigenvectores pertenecientes al eigenvalor λ1 = −1 forman un subespacio unidimensional con el vector base
. Así, los eigenvectores pertenecientes al eigenvalor λ1 = −1 forman un subespacio unidimensional con el vector base ![]() .
.
Ahora sustituyendo ![]() en la ecuación
en la ecuación ![]() obtenemos
obtenemos
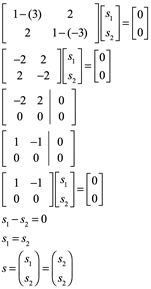
Dejando ![]() en
en ![]() Nosotros encontramos que
Nosotros encontramos que ![]() es un eigenvector de la matriz
es un eigenvector de la matriz ![]() asociado con el eigenvalor
asociado con el eigenvalor ![]() .
.
![]()
Las soluciones de esta ecuación son todos los múltiplos de s2 = (1, 1) T.
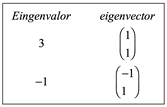
 12.26.31.png)
 13.34.30.png)
Ejemplo 2: Muestre que ![]() s un eigenvector de
s un eigenvector de ![]() y encuentre el eigenvalor de A correspondiente.
y encuentre el eigenvalor de A correspondiente.
![]()
Calculamos
![]()
De lo cual se sigue que x es un eigenvector de A correspondiente al eigenvalor -2.
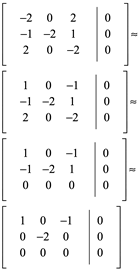
Ejemplo 3: Demuestre que 3 es un eigenvalor de
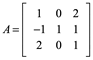
y determine eigenvector correspondiente
Debemos demostrar que existe un vector x distinto de cero tal que Ax=3x. Sin embargo esta ecuación es equivalente a la ecuación (A-3I)x=0 , de modo que necesitamos calcular el espacio nulo de la matriz A-3I=0.
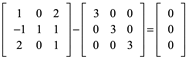
Si

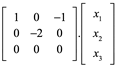
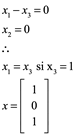
 18.20.46.png)
5.3 Método de Cramer
Sea A una matriz invertible de nxn y sea b un vector en ![]() , es decir
, es decir ![]() . Entonces, la única solución del sistema Ax=b está dada por:
. Entonces, la única solución del sistema Ax=b está dada por:
![]()
Ejemplo 4: Para el siguiente sistema, calcule la solución x,y,z por el método de Cramer
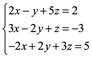

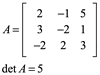

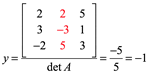
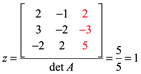
Por lo tanto la solución es (-2,-1,1) para de mostrarlo vaciamos en la primera ecuación por ejemplo:
![]()
____________________________________
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Lizbeth Guadalupe Villalon Magallan
Mónica Rico Reyes
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán